4.4 Matematikos ir informatikos institutas
4.4.1 Įvadas
Naujas mokslinių ir taikomųjų balso technologijų tyrimo darbų etapas prasidėjo Matematikos ir informatikos institute 1990 metais, kai Lietuvos teismo ekspertizės institutas paprašė mokslinės pagalbos sprendžiant fonoskopinės ekspertizės problemas ten įkurtame Fonoskopinių ekspertizių skyriuje. Buvo sukurta keletas kalbančiojo identifikavimo ir verifikavimo pagal balsą metodų, kurie yra naudojami atliekant fonoskopines ekspertizes. Šis bendradarbiavimas tęsiasi iki šiol.
Vykdant Lietuvių kalbos informacinėje visuomenėje 2000-2006 metų programą 2000 metais pradėti sistemingi lietuvių kalbos automatinio atpažinimo tyrimai. Šiuose tyrimuose taip pat dalyvauja Vytauto Didžiojo universiteto ir Lietuvos teismo ekspertizės centro mokslininkai. Per du metus buvo sukurta atskirai sakomų lietuvių kalbos žodžių automatinio atpažinimo, naudojant kalbos pavyzdžių dinaminį laiko skalės kraipymą, modeliavimo programinė įranga, atliekami atpažinimo kokybės gerinimo tyrimai. Kuriamas lietuvių kalbos automatinio atpažinimo sistemos prototipas.
4.4.2 Automatinis atskirai
sakomų lietuvių kalbos žodžių atpažinimas, naudojant kalbos
pavyzdžių dinaminį laiko skalės kraipymą
Sprendžiant atskirai
sakomų žodžių atpažinimo uždavinį reikia
sutapatinti laike ir palyginti, kiek
atpažįstamas balso pavyzdys yra panašus į etaloninį
balso pavyzdį. Atpažįstamo ir etaloninio balso
pavyzdžių trukmės ir atskitų garsų trukmės juose
paprastai skiriasi, todėl jų palyginimas yra gana sudėtingas
uždavinys. Šio uždavinio sprendimui yra naudojamas kalbos
pavyzdžių dinaminis laiko skalės kraipymas, kuris remiasi
dinaminio programavimo metodu. Dinaminis laiko skalės kraipymas yra
pailiustruotas 1 pav.

1.
Pav. Dviejų pasakytų
žodžių “aštuoni” palyginimo, naudojant dinaminį laiko
skalės kraipymą, iliustracija.
Šiame paveikslėlyje nupiešto stačiakampio abscisių ašyje yra išdėstyti etaloninio žodžio požymiai, ordinačių ašyje – testinio žodžio požymiai. Etaloninio žodžio ir atpažįstamojo (lyginamojo) žodžio signalų grafikai yra nupiešti apačioje. Nupieštas lygiagretainis žymi geriausios požymių laiko skalės kraipymo trajektorijos paieškos sritį. Lygiagretainio įstrižainė žymi tiesinio laiko skalės kraipymo trajektoriją. Vingiuota kreivė žymi dinaminio (netiesinio) laiko skalės kraipymo trajektoriją. Ši trajektorija atitinka geriausią etaloninio ir lyginamojo žodžių požymių sutapatinimą. Sutapatinimo kokybės rodiklis yra vidutiniai iškraipymai, paskaičiuoti esant geriausiai požymių laiko skalės kraipymo trajektorijai. Kuo vidutiniai iškraipymai mažesni, tuo sutapatinimas geresnis. Lyginant žodžius, kur ištartas tas pats tekstas, vidutiniai iškraipymai yra dažniausiai mažesni negu lyginant žodžius, kur ištartas skirtingas tekstas. Vadinasi, jeigu norime atpažinti žodį, mes, naudodami dinaminį laiko skalės kraipymą, turime palyginti jį su visų žodyno žodžių etalonais ir etalonas, kuriam vidutiniai iškraipymai bus mažiausi, bus atpažintas žodis. Plačiau apie šiuos tyrimus galima pasiskaityti nurodytoje literatūroje [1-8].
Praktiniam susipažinimui su šia technologija mes pateikiame atskirai sakomų lietuvių kalbos žodžių automatinio atpažinimo, naudojant kalbos pavyzdžių dinaminį laiko skalės kraipymą, modeliavimo programą. Šios programos aprašymas yra sekančiame skyrelyje.
Literatūra
1. Automatinio lietuvių šnekos atpažinimo darbai, Lietuvių kalbos informacinėje visuomenėje 2000–2006 metų programos ataskaita, Matematikos ir informatikos institutas, 2000 metai, 36 psl.
2. Automatinio lietuvių šnekos atpažinimo darbai, Lietuvių kalbos informacinėje visuomenėje 2000–2006 metų programos ataskaita, Matematikos ir informatikos institutas, 2001 metų I ketvirtis, 88 psl.
3. Automatinio lietuvių šnekos atpažinimo darbai, Lietuvių kalbos informacinėje visuomenėje 2000–2006 metų programos ataskaita, Matematikos ir informatikos institutas, 2001 metų II ketvirtis, 117 psl.
4. Automatinio lietuvių šnekos atpažinimo darbai, Lietuvių kalbos informacinėje visuomenėje 2000–2006 metų programos ataskaita, Matematikos ir informatikos institutas, 2001 metų III ketvirtis, 58 psl.
5. Automatinio lietuvių šnekos atpažinimo darbai, Lietuvių kalbos informacinėje visuomenėje 2000–2006 metų programos ataskaita, Matematikos ir informatikos institutas, 2001 metų IV ketvirtis, 131 psl.
- Lipeika,
J. Lipeikienė, L. Telksnys, Development of isolated word speech
recognition system, INFORMATICA,
13(1), 2002.
- Lipeika,
J. Lipeikienė, Laiko skalės išlyginimas kalbos ir
kalbančiojo atpažinime, Lietuvos matematikos rinkinys, T.41,
Specialusis numeris, Lietuvos matem. draugijos XLII konf. mokslo darbai,
2001.
8.
Lipeika, J. Lipeikienė, Atskirai
sakomų žodžių atpažinimo tyrimas, “BIOMEDICININĖ
INŽINERIJA”, Tarpt. konf. pranešimų medžiaga, Kaunas,
Technologija, 2001, 32-35 psl.
4.4.3 Atskirai sakomų žodžių atpažinimo modeliavimo programos
aprašymas
Kad galėtume atlikti atskirai sakomų
žodžių atpažinimo tyrimus natūraliomis sąlygomis
ir esant laisvai pasirenkamam atpažįstamų žodžių
žodynui, mes pradėjome kurti atskirai sakomų
žodžių atpažinimo modeliavimo programinę įrangą.
Šiame skyriuje yra aprašoma atpažinimo modeliavimo programa,
sukurta Borland C++ algoritminėje kalboje Windows aplinkai.
Naudojant
sukurtą atpažinimo modeliavimo programą, galima atlikti tokias
funkcijas:
·
Pasirinkti
norimus atpažinimo sistemos parametrus
·
Per
mikrofoną įrašyti atpažįstamus žodžius ir
žodžių etalonus
·
Išsaugoti
įrašytus žodžius .wav formato failuose
·
Klausyti
balso įrašus
·
Surasti
žodžių pradžios ir galo taškus ir išskirti
tiesinės prognozės modelio požymius
·
Išsaugoti
ir nuskaityti atpažistamų žodžių požymius
·
Išsaugoti
ir nuskaityti atpažistamų žodžių etalonus
·
Atlikti
dviejų žodžių požymių palyginimą naudojant
dinaminį laiko skalės išlyginimą
·
Atpažinti
testinius žodžius
Ši programinė
įranga suteikia daug galimybių atliekant atskirai sakomų žodžių
atpažinimo tyrimus. Toliau mes panagrinėsime šias galimybes
smulkiau.
4.4.3.1 Pagrindinis programos langas
Paleidus atskirai sakomų žodžių atpažinimo modeliavimo programą Recognition, atsidaro pagrindinis programos langas, pavaizduotas 1 pav.

1 Pav. Pagrindinis
programos Recognition langas.
Pagrindiniame
lange yra atvaizduojami programos darbo rezultatai. Jame taip pat yra visi
pagrindiniai valdymo mygtukai:
Options -
norimų
atpažinimo sistemos parametrų nustatymas (atpažinimo sistemos
konfigūravimas).
Record - atpažįstamų
žodžių ir žodžių etalonų įrašymas
per mikrofoną.
Play Sound - įrašytų
žodžių, saugomų *.wav failuose pasiklausymas.
Read_Save_Templates - atpažįstamų ir etaloninių
žodžių požymių išsaugojimas arba nuskaitymas.
Add/Del_Templates - žodžių
etalonų papildymas naujais etalonais arba
žodžių
etalonų pašalinimas iš etalonų sąrašo.
Add/Del_Test - testinių žodžių
sąrašo papildymas naujais testiniais žodžiais arba
testinių žodžių pašalinimas iš testinių
žodžių sąrašo.
DTW -
testinio žodžio palyginimas su etaloniniu žodžiu
naudojant dinaminį laiko skalės išlyginimą ir palyginimo
rezultatų atvaizdavimas.
Recognition - testinio žodžio palyginimas su etaloniniais
žodžiais (atpažinimas) ir palyginimo rezultatų
atvaizdavimas.
Exit -
programos darbo užbaigimas.
Help -
pagalba.
Toliau mes apibūdinsime visus
šiuos valdymo mygtukus smulkiau ir parodysime, kaip jais naudotis,
atliekant kalbos atpažinimo eksperimentus.
4.4.3.2 Atpažinimo sistemos
parametrų nustatymas - atpažinimo sistemos konfigūravimas
Atpažinimo
sistemos konfigūravimas yra atliekamas su pele nuspaudus mygtuką Options. Paspaudus šį
mygtuką, atsidaro langelis su užrašu Parameters. Paspaudus mygtuką Parameters, atsidaro
atpažinimo sistemos parametrų langas, pavaizduotas 2 pav.
Šviesiuose parametrų lango
langeliuose yra surašyti iš anksto parinkti atpažinimo sistemos
parametrai, kuriuos galima pakeisti,
surenkant iš klaviatūros norimus parametrus.
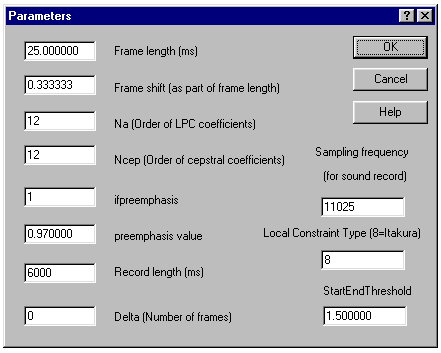
2 Pav. Atpažinimo sistemos parametrų langas.
Ties
kiekvieno parametro langeliu yra užrašas, nusakantis šio
parametro prasmę:
Frame length [ms] – analizės
kadro ilgis milisekundėmis.
Frame shift [as part of frame length] – analizės kadro žingsnis,
išreikštas analizės kadro ilgio dalimi.
Na [Order of LPC coefficients] - tiesinės prognozės
(LPC) modelio eilė. Tiesinės prognozės modelis yra naudojamas,
išskiriant požymius iš žodžių garso failų ir
juos palyginant.
Ncep [Order of cepstral coefficients] – kepstro koeficientų, paskaičiuotų
iš tiesinės prognozės modelio koeficientų, skaičius.
Atpažinimas, naudojant kepstro koeficientus, dar nerealizuotas.
ifpreemphasis – parametras,
įjungiantis/išjungiantis kalbos signalo pradinę filtraciją.
Kai šis parametras yra lygus 1, filtracija įjungta, kai 0 –
išjungta.
preemphasis value – pradinės
filtracijos koeficiento reikšmė ![]() . Pradinės filtracijos filtro sistemos funkcija yra
. Pradinės filtracijos filtro sistemos funkcija yra
![]() ,
,![]()
atitinkanti skirtuminę lygtį
![]() ,
,
kur ![]() yra nefiltruotas kalbos
signalas.
yra nefiltruotas kalbos
signalas.
Record length [ms] - įrašymo laikas
milisekundėmis, įrašant kalbos signalą per mikrofoną.
Delta [Number of frames] – kadrų skaičiaus intervalas, kuriame ieškoma pradžios ir
galo taškų, atliekant dinaminį laiko skalės
išlyginimą.
Sampling frequency [for sound record] – diskretizavimo
dažnis, įrašant balsą per mikrofoną.
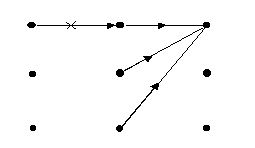
Local Constraints Type [8=Itakura] – lokalaus tolydumo apribojimų tipas, atliekant
dinaminį laiko skalės išlyginimą. Iš anksto
nustatyti yra Itakuros apribojimai – 8 tipas, kaip pavaizduota 3 pav.
3 Pav. Itakuros lokalaus tolydumo apribojimai, kurie yra naudojami dinaminio laiko skalės kraipymo funkcijoje.
Be šių apribojimų,
galima parinkti trečio ir penkto tipo apribojimus. Jie yra pavaizduoti 4
ir 5 pav.
4 Pav. Trečio tipo lokalaus tolydumo apribojimai, kurie yra naudojami dinaminio laiko skalės kraipymo funkcijoje.
5 Pav. Penkto tipo lokalaus tolydumo apribojimai, kurie yra naudojami dinaminio laiko skalės kraipymo funkcijoje.
Pastebėsime, kad Itakuros
apribojimai yra nesimetriniai ir, sukeitus testinį pavyzdį su
etaloniniu, vidutiniai iškraipymai pasikeis.
StartEndThreshold - energijos slenkstis
žodžio pradžios ir
galo taškų suradimui kalbos signale. Tai bene dažniausiai
keičiamas parametras dirbant su šia programine įranga. Jis labai
priklauso nuo triukšmo lygio ir kalbinės aplinkos fono.
Pakeitus
kokius nors sistemos parametrus ir nuspaudus mygtuką OK, skaičiavimai toliau vyksta su naujai parinktais
parametrais. Paspaudus mygtuką Cancel, lieka seni sistemos parametrai.
4.4.3.3 Atpažįstamų žodžių ir
žodžių etalonų įrašymas per mikrofoną
Žodžio
įrašymas per mikrofoną prasideda paspaudus mygtuką Record. Spalvinis indikatorius rodo
kokia dalis įrašymo laiko jau yra išnaudota. Pasibaigus
įrašymo laikui vietoje mygtuko užrašo Record atsiranda užrašas Record finished ir visas įrašymo trukmės
indikatorius nusidažo raudonai. Be to, po įrašymo trukmės
indikatorium atsiranda darbinis langas su užrašu If you want to save record, introduce file name Extention .wav will be
added to file name (Jei norite išsaugoti įrašą,
įveskite failo vardą. Plėtinys .wav bus pridėtas prie failo
vardo), kaip parodyta 6 pav.
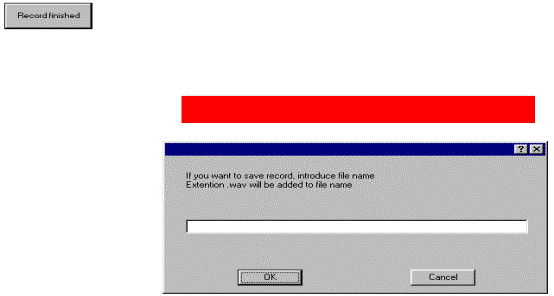
6 Pav. Programos langas
įrašymo per mikrofoną metu.
Baltame langelyje surinkus
suteiktą balso įrašui pavadinimą ir paspaudus OK, balso įrašas
išsaugomas. Paspaudus mygtuką Cancel,
balso įrašas neišsaugomas. Balso įrašai yra
saugomi toje pačioje direktorijoje kaip ir pati programa.
4.4.3.4 Balso įrašų
pasiklausymas
Paspaudus
mygtuką Play Sound, atsidaro standartinis failų
atidarymo langas, kuriame reikia surasti garso failą (.wav), kurį mes
norime klausyti. Pažymėjus garso failą ir paspaudus mygtuką
Open, prasideda garso failo
išvedimas į ausines arba garsiakalbį. Išvedimą galima
sustabdyti paspaudus mygtuką OK po
užrašu Press to stop playing (Spausk,
jei nori sustabdyti) išvedimo metu atsiradusiame langelyje su pavadinimu Playing. Pasibaigus garso
išvedimui taip pat reikia paspausti šį mygtuką.
4.4.3.5 Atpažįstamų
žodžių ir etalonų požymių išsaugojimas ir
nuskaitymas
Dirbant
su šia programine įranga, yra patogu išsaugoti
atpažįstamų žodžių ir etalonų išskirtus
požymius. Atpažįstamų žodžių požymiai
yra saugomi faile templat.tst o etalonų požymiai yra saugomi faile templat.tpl.
Prieš nutraukiant programos darbą, reikia juos išsaugoti.
Paleidus programą, reikia juos nuskaityti. Atpažįstamų
žodžių ir etalonų požymių nuskaitymas ir
išsaugojimas yra atliekamas nuspaudus mygtuką Read_Save_Templates, kaip pavaizduota 7 pav.
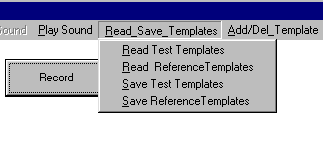
7 Pav. Atpažįstamų
žodžių ir etalonų požymių nuskaitymas ir
išsaugojimas.
Nuspaudus
mygtuką, atsidaro darbinis langelis, kuriame yra keturios galimybės:
Read Test Templates – nuskaityti
testinių žodžių požymius;
Read Reference Templates –
nuskaityti etaloninių žodžių požymius;
Save Test Templates – išsaugoti
testinių žodžių požymius;
Save Reference Templates –
išsaugoti etaloninių žodžių požymius.
4.4.3.6 Žodžių pradžios ir galo taškų
nustatymas ir požymių išskyrimas
Jeigu norime išskirti požymius iš
testinių žodžių garso failų, spaudžiame
mygtuką Add/Del_Test,
jeigu iš etaloninių - Add/Del_Templates.
Tada atsidaro darbinis langelis, kaip pavaizduota 8 pav., testiniam
žodžiui arba, kaip pavaizduota 9 pav., etaloniniam žodžiui.
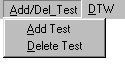
8 Pav. Darbinis langelis testinio
žodžio požymių išskyrimui.
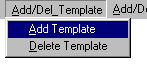
9 Pav. Darbinis langelis etaloninio
žodžio požymių išskyrimui.
Spaudžiame atitinkamai mygtuką Add Test arba Add Template ir atsidaro standartinis failo atidarymo langas, kuriame
susirandame norimą žodžio garso failą (su plėtiniu
.wav). Atidarius garso failą, pagrindiniame lange atsiranda vaizdas, kaip
parodyta 10 pav.
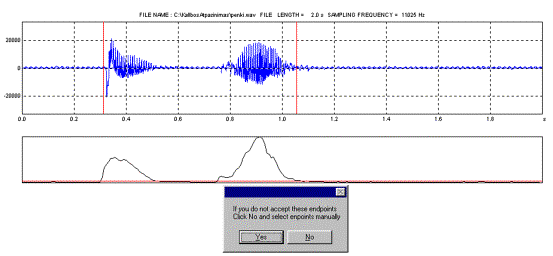
10 Pav. Vaizdas
pagrindiniame programos lange atidarius žodžio garso failą.
10
pav. yra pavaizduotas žodžio “penki” garso signalas, saugomas garso
faile “penki.wav”. Po signalo kreive yra pavaizuotas signalo
energijos grafikas, kuriuo remiantis yra automatiškai nustatomi
žodžio pradžios ir galo taškai. Raudona horizontalia
linija vaizduoja energijos
slenkstį žodžio pradžios ir galo taškų
nustatymui, kuris yra parinktas konfigūruojant atpažinimo
sistemą (žiūr. skyrelį 4.4.3.2). Žodžio signalo
trumpalaikė energija yra lyginama su šiuo slenksčiu ir pagal tam
tikrą algoritmą yra surandami žodžio pradžios ir galo
taškai. Virš signalo kreivės yra užrašytas
analizuojamo žodžio signalo failo vardas, jo trukmė
sekundėmis ir diskretizacijos dažnis. Vertikalios raudonos linijos
žymi surastus žodžio pradžios ir galo taškus.
Jeigu
žodžio pradžios ir galo taškai yra surasti gerai, mes
galime spausti mygtuką Yes atsiradusiame
darbiniame lange. Tada atsidaro darbinis langas, kaip pavaizduota 11 pav.
Šiame lange po užrašu Speaker
Name - (kalbėtojo vardas) yra
baltas langelis, kuriame reikia įvesti kalbėtojo vardą, po
užrašu Spoken phrase - (pasakyta
frazė) yra baltas langelis,
kuriame reikia įvesti pasakytą žodį. Neužmirškite
prieš vesdami tekstą į šiuos langelius pirma ten nuvesti
pelės kursorių ir paspausti kairį pelės klavišą.
Jeigu mes dėl kokių nors priežasčių nenorime
išsaugoti šio žodžio požymių, šių
langelių galime nepildyti ir paspausti mygtuką Cancel.
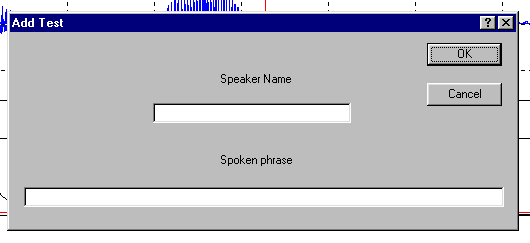
11 Pav. Kalbėtojo vardo ir pasakyto teksto
priskyrimas analizuojamam garso failui.
Jeigu žodžio pradžios ir/arba galo taškai yra
surasti neteisingai, mes turime dvi galimybes.
Pirma galimybė – 10 pav.
pavaizduotame darbiniame langelyje paspausti mygtuką Yes, o 11 pav. pavaizduotame lange paspausti mygtuką Cancel. Tuo atveju išskirti
požymiai nėra išsaugomi ir šio žodžio
požymių išskyrimą mes galime pakartoti iš naujo. Tam
reikia pakeisti energijos slenkstį atpažinimo sistemos parametrų
nustatyme (4.4.3.2 skyrelis). Jeigu
automatiškai nustatant žodžio pradžios ir galo taškus
buvo “nukirpti” žodžio pradžia ir/arba galas, slenkstį
reikia didinti, priešingu atveju – mažinti.
Antra galimybė – nustatyti
slenkstį rankiniu būdu, naudojant pelę . Tuo atveju 10 pav.
pavaizduotame langelyje spaudžiame mygtuką No. Tada pelė tampa aktyvi ir, judinant pelę,
išilgai signalo kreivės slankioja vertikali linija. Užvedę
šią liniją ant žodžio pradžios, paspaudžiam
kairį pelės klavišą, pasižymi žodžio
pradžia. Tada užvedam liniją ant žodžio galo ir
vėl paspaudžiam kairį pelės klavišą,
pasižymi žodžio galas ir atsiranda mums pažįstamas
langas, pavaizduotas 11 pav. Toliau eina veiksmai, kurie buvo atliekami
automatiškai nustatant žodžio pradžios ir galo taškus.
Jeigu mes užmirštame ką nors įvesti 11 pav. pavaizduotame
lange ir paspaudžiame mygtuką OK,
atsiranda langelis – pranešimas No
speaker name! – (kalbėtojas neturi vardo),
pavaizduotas 12 pav.

12 Pav. Pranešimas apie kokius nors
neatliktus veiksmus.
Tokiu atveju mums belieka paspausti mygtuką OK, požymiai nėra išsaugomi ir belieka požymių išskyrimą tam žodžiui pakartoti iš naujo.
4.4.3.7 Testinių arba etaloninių žodžių požymių pašalinimas iš saugomų požymių failų
Kartais susidaro situacija, kad
kokių nors testinių arba etaloninių žodžių
požymiai mūsų nebedomina ir mes norime juos pašalinti.
Tokiu atveju testinių žodžių požymių
pašalinimui reikia spausti mygtuką Add/Del_Test, o etaloninių žodžių
požymių pašalinimui reikia spausti mygtuką Add/Del_Templates. Tada
testinių žodžių požymių pašalinimui atsidaro
langelis, pavaizduotas 8 pav., o etaloninių žodžių požymių pašalinimui atsidaro
langelis, pavaizduotas 9 pav. Tada spaudžiam atitinkamai mygtuką Delete Test arba Delete Template ir atsidaro
langas, pavaizduotas 13 pav. Šiame paveikslėlyje yra pavaizduotas
etaloninio žodžio požymių pašalinimo langas.
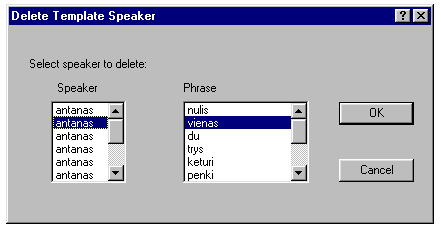
13 Pav. Etaloninio žodžio
požymių pašalinimo langas.
Užvedus pelės
kursorių ant norimo pašalinti žodžio ir paspaudus
kairį pelės klavišą, šis žodis pasižymi, o
paspaudus mygtuką OK šio žodžio požymiai yra
pašalinami.
4.4.3.8 Testinio žodžio palyginimas su etaloniniu žodžiu, naudojant dinaminį laiko skalės išlyginimą, ir palyginimo rezultatų atvaizdavimas
Šis
režimas yra naudojamas palyginti kaip gerai yra sutapatinamas testinis ir
etaloninis žodžiai, pasitikrinti, ar gerai yra nustatyti
žodžių pradžios ir galo taškai, kodėl
žodžių palyginimo metu gautas būtent toks atstumas tarp
žodžių. Šis režimas palengvina atskirai sakomų
žodžių atpažinimo rezultatų interpretaciją.
Kad
pasinaudotume šiuo režimu, pagrindiniame programos lange reikia
spausti mygtuką DTW. Tada
atsidaro testinio ir etaloninio žodžių požymių
atidarymo langas, kaip pavaizduota 14 pav. Šiame lange pelės pagalba
mes pasižymime testinį ir etaloninį žodžius, kuriuos
norime palyginti, ir, paspaudus mygtuką OK, pagrindiniame programos lange yra atvaizduojami palyginimo
rezultatai, kaip parodyta 15 pav.
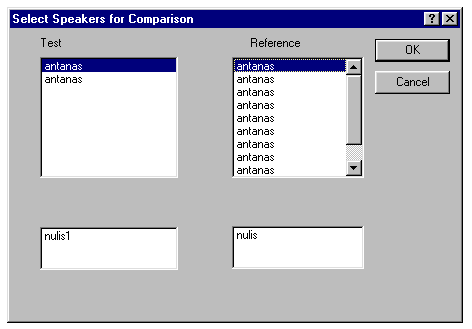
14 Pav. Testinio ir etaloninio
žodžių požymių atidarymo langas.
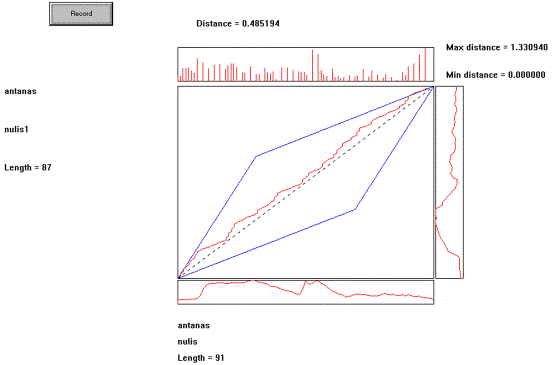
15 Pav. Testinio ir etaloninio
žodžių požymių palyginimo rezultatai. Testinis
žodis “nulis” etaloninis žodis “nulis”.
Šiame paveikslėlyje
yra atvaizduotas testinio žodžio “nulis” (sąlyginis pavadinimas
nulis1) palyginimas su etaloniniu žodžiu “nulis” (sąlyginis
pavadinimas nulis). Kalbėtojas yra “antanas”. Abscisių ašyje yra
vaizduojamas etaloninio žodžio laikas, ordinačių –
testinio. Taip pat yra užrašyta kiek požymių vektorių
yra etaloniniame žodyje ir kiek testiniame. Šalia pagrindinio grafiko
yra pavaizduotos etaloninio ir testinio žodžių energijos
kreivės. Pagrindiniame grafike mėlyna spalva yra pavaizduotos
optimalaus laiko skalės išlyginimo trajektorijos paieškos ribos.
Punktyrinė linija žymi tiesinio laiko skalės išlyginimo
trajektoriją. Šalia šios trajektorijos raudona spalva yra
pavaizduota optimalaus laiko
skalės išlyginimo trajektorija. Virš pagrindinio grafiko yra
pavaizduoti atstumai tarp požymių vektorių, kurių indeksai
yra taškai, kuriuos kerta pavaizduota
optimalaus laiko skalės išlyginimo trajektorija. Jeigu šių
atstumų reikšmių diapazonas yra nedidelis, tai vizualiai liudija
apie lyginamų žodžių panašumą. Šio grafiko
dešinėje yra užrašytos šių atstumų minimali
ir maksimali reikšmės. Jeigu žodžių pradžios
ir/arba galo taškai yra nustatyti neteisingai, tose vietose gaunami
atstumai yra labai dideli ir iš grafiko tas gerai matosi.
Pagrindinis dviejų
žodžių palyginimo rodiklis yra vidutinis atstumas tarp
šių žodžių, esant optimaliam laiko skalės
išlyginimui. Jis yra užrašytas virš grafiko (šiuo
atveju jis yra “Distance =
0.485194”).
Jeigu yra lyginami
skirtingi žodžiai, vidutinis atstumas gaunamas daug didesnis, kaip
pavaizduota 16 pav.
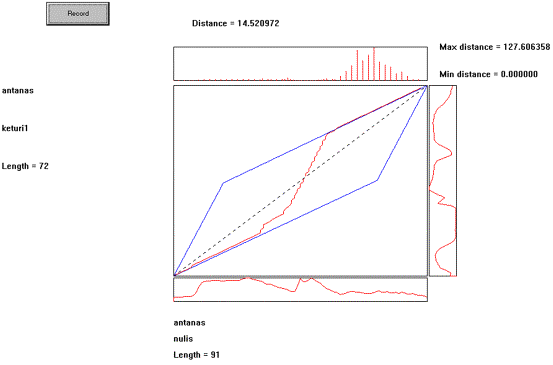
16 Pav. Testinio ir
etaloninio žodžių požymių palyginimo rezultatai.
Testinis žodis “keturi”, etaloninis žodis “nulis”.
Šiame
pavyzdyje testinis žodis yra “keturi” (sąlyginis pavadinimas
“keturi1”), etaloninis “nulis”. Kaip matome,
optimalaus laiko skalės išlyginimo trajektorijos gale atstumai
tarp požymių vektorių yra labai dideli ir vidutinis atstumas
tarp žodžių irgi labai didelis (“Distance = 14.520972” ). Čia ir yra visa atskirai
sakomų žodžių atpažinimo esmė. Lyginant
testinį žodį su žodžių etalonais optimalaus laiko
skalės išlyginimo trajektorijai vidutinis atstumas paprastai gaunamas
mažiausias, kai testinis ir etaloninis žodžiai yra tas pats
žodis, nors tai ir kitas ištarimas.
4.4.3.9 Atpažinimas
Atpažinimo metu testinis žodis yra
lyginamas su visų etalonų sąraše esančių
žodžių etalonais, naudojant optimalų laiko skalės
išlyginimą, ir skaičiuojamas vidutinis atstumas tarp testinio
žodžio ir kiekvieno etaloninio žodžio. Etaloninis
žodis, iki kurio vidutinis atstumas yra mažiausias, yra laikomas
atpažintu žodžiu.
Kad
atliktume žodžių atpažinimą, reikia paspausti
mygtuką Recognition.
Tada atsidaro langas, kuriame yra testinių žodžių
sąrašas, kaip pavaizduota 17 pav.
17 Pav. Testinių
žodžių sąrašo langas.
Su pele pagalba
pažymėjus eilutę stulpelyje Speaker
– kalbėtojas, kitame stulpelyje Spoken
phrase atsiranda tą eilutę atitinkančio testinio
žodžio sąlyginis pavadinimas. Paspaudus mygtuką OK, atpažinimo rezultatai yra
atvaizduojami, kaip parodyta 18 pav.
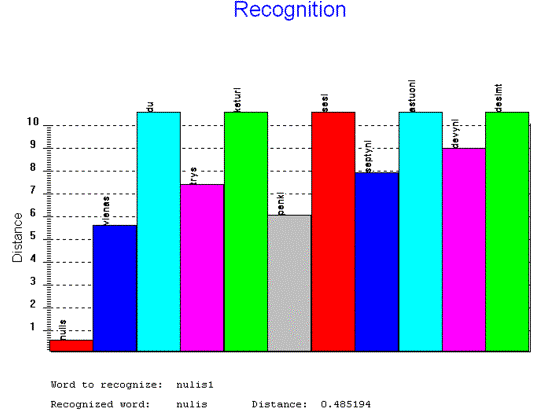
18 Pav. Žodžio “nulis” atpažinimo
rezultatų atvaizdavimas.
Šiame paveikslėlyje yra atvaizduoti žodžio “nulis1” atpažinimo rezultatai. Vertikalūs stulpeliai žymi žodžio “nulis1 “ vidutinį atstumą iki etalonų. Virš stulpelių surašyti etalonai, iki kurių yra paskaičiuoti atstumai. Po grafiku yra parašytas testinio žodžio sąlyginis pavadinimas (“Word to recognize: nulis1” – Atpažįstamas žodis: nulis1) ir atpažintas žodis (“Recognized word: nulis Distance: 0.485194” – Atpažintas žodis: nulis Atstumas: 0.485194).
Kaip
matome, atstumas iki etalono nulis yra
mažiausias. Atstumai iki kitų etalonų yra gerokai didesni. Jeigu
atstumas yra didesnis negu 10.5, jis yra apribotas iki 10.5, kad geriau
matytume mažus atstumus – artimiausio etalono konkurentus.
19 pav. yra pavaizduoti
žodžio “keturi” atpažinimo rezultatai.
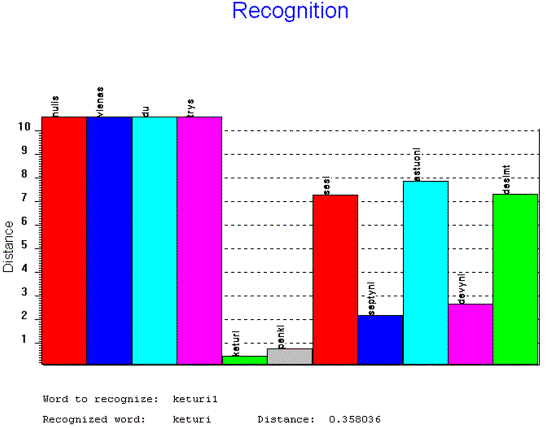
19 Pav. Žodžio “keturi” atpažinimo rezultatų
atvaizdavimas.
Žodis “keturi” pagal
tarimą yra gana panašus į žodį “penki” todėl
artimiausias konkurentas etalonui “keturi” ir yra etalonas “penki”. Tolimiausi
etalonai priklauso žodžiams “nulis”, “vienas”, “du” ir “trys”.
Norint baigti progamos
darbą, pirmiausia reikia išsaugoti išskirtus požymius
(4.4.3.5 skyrelis) o po to paspausti mygtuką Exit ir po to atsiradusiame langelyje paspausti mygtuką
OK.
Sukurta programinė
įranga nėra galutinai užbaigta ir kai ką reikia tobulinti,
pvz., žodžio pradžios ir galo taškų suradimą.
Tačiau, nežiūrint į trūkumus, ją galima naudoti
atskirai sakomų žodžių atpažinimo eksperimentiniams
tyrimams. Ypač patraukli yra galimybė įkalbėti
žodžius per mikrofoną ir čia pat juos atpažinti. Be to
yra patogi galimybė pačiam pasirinkti kokį tik nori
atpažįstamų žodžių rinkinį ir būti
nepriklausomam nuo jokių balsų bazių.
Jeigu turite klausimų,
pastabų rašykite Antanui Lipeikai elektroniniu paštu adresu: lipeika@ktl.mii.lt. Kviečiame visus
besidominčius išbandyti šią programą.
4.4.4 Kalbančiojo atpažinimas pagal balsą
Kalbančiojo atpažinimas pagal balsą yra skirstomas į kalbančiojo identifikavimą ir verifikavimą (1 pav.). Savo ruožtu, tiek kalbančiojo identifikavimas tiek verifikavimas gali būti priklausomas arba nepriklausomas nuo pasakyto teksto.
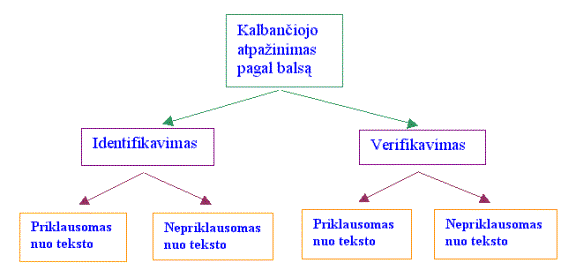
1. Pav. Kalbančiojo atpažinimo pagal balsą klasifikacija.
4.4.4.1 Kalbančiojo
identifikavimas
Kalbančiojo identifikavimas yra toks uždavinys, kai mes turime N asmenų (įtariamųjų) balso įrašus ir nežinomo asmens balso įrašą X. Mums reikia atsakyti į klausimą, kurio iš įtariamųjų balsas yra panašiausias į nežinomo asmens balsą (2 pav.).
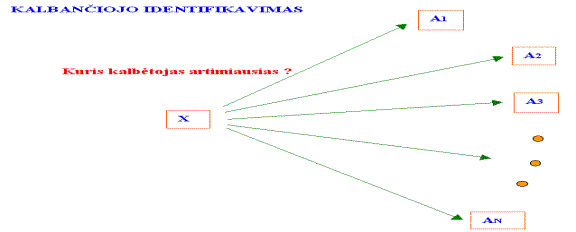
2. Pav. Kalbančiojo
identifikavimo uždavinio iliustracija.
Mes tyrėme nepriklausomus
nuo pasakyto teksto kalbančiojo atpažinimo metodus. Požymiai
kalbančiojo atpažinimui buvo išskiriami iš vokalizuotų
garsų pseudostacionarių intervalų [1]. Tai buvo daroma remiantis
prielaida, kad tariant
vokalizuotą garsą trumpam
užfiksuojama kalbos trakto organų padėtis, dėl
ko yra galimybė naudojantis balso
įrašu “išmatuoti” kalbos trakto parametrus ir kartu
identifikuoti kalbantįjį. Buvo sukurti trys nepriklausomi nuo
pasakyto teksto kalbančiojo identifikavimo metodai.
Identifikavimo metodas, besiremiantis vidutinio atstumo tarp klasterių apskaičiavimu
Tarkime turime tiriamojo kalbančiojo (X) ![]() stacionarių
intervalų ir
stacionarių
intervalų ir ![]() , lyginamųjų stacionarių intervalų.
Apskaičiuokime visus galimus atstumus
, lyginamųjų stacionarių intervalų.
Apskaičiuokime visus galimus atstumus ![]() tarp tiriamojo X ir
lyginamųjų
tarp tiriamojo X ir
lyginamųjų ![]() , stacionarių intervalų. Tada vidutinį
atstumą tarp klasterio, apibūdinančio tiriamąjį X, ir
apibūdinančio lyginamąjį
, stacionarių intervalų. Tada vidutinį
atstumą tarp klasterio, apibūdinančio tiriamąjį X, ir
apibūdinančio lyginamąjį ![]() klasterio, galima
paskaičiuoti pagal [2] taip:
klasterio, galima
paskaičiuoti pagal [2] taip:
![]() .
.
Čia ![]() ir
ir ![]() atitinkamai yra tiriamojo kalbančiojo X ir lyginamųjų
atitinkamai yra tiriamojo kalbančiojo X ir lyginamųjų ![]() kadrų
skaičius kalbos fonogramoje;
kadrų
skaičius kalbos fonogramoje; ![]() - atstumas tarp kadrų.
- atstumas tarp kadrų.
Apskaičiavę
vidutinį atstumą tarp tiriamojo kalbančiojo X ir visų lyginamųjų ![]() , galime rasti “artimiausią” lyginamąjį,
sulyginę vidutinius atstumus
, galime rasti “artimiausią” lyginamąjį,
sulyginę vidutinius atstumus
![]() .
.
Plačiau apie šį metodą galima
pasiskaityti straipsniuose [1], [2].
Identifikavimo metodas, besiremiantis vektoriniu kvantavimu
Šio metodo esmė yra tame, kad
kalbančiųjų balso požymių vektoriai yra
klasterizuojami naudojant vektorinio kvantavimo metodą ir
požymių vektoriai yra pakeičiami gautų klasterių
centrais. Tiriamojo ir lyginamųjų (įtariamųjų) balso
požymių klasterių centrams palyginti naudojamas vidutinis
atstumas, apibrėžtas ankstesniame metode.
Vektorinio kvantavimo metodo privalumas yra
tame, kad sumažėja lyginamų požymių vektorių
skaičius ir žymiai pagreitėja skaičiavimai. Tai yra svarbu,
kai lyginamųjų (įtariamųjų) sąrašas yra
labai ilgas.
Plačiau apie šį metodą galima
pasiskaityti straipsniuose [3], [4].
Identifikavimo metodas, besiremiantis
kalbos trakto ir sužadinimo
signalo tiesinės prognozės parametrais
Du pirmieji
aptarti kalbančiojo identifikavimo metodai kaip požymius naudoja
tiesinės prognozės modelio parametrus arba kepstro koeficientus, turinčius informacijos apie kalbos
traktą. Tačiau juose neatsispindi informacija apie kalbos trakto
sužadinimo signalą. Vokalizuotų garsų sužadinimo
signalas taip pat charakterizuoja kalbantįjį.
Šį
uždavinį galima išspręsti ir kalbos traktą, ir
sužadinimo signalą vaizduojant tiesinės prognozės modeliu.
Išskyrus balso trakto tiesinės prognozės modelio požymius,
naudojant atvirkštinę filtraciją, yra atkuriamas balso
traktą žadinantis signalas. Šis signalas yra išretinamas ir
vaizduojamas tiesinės prognozės modeliu. Tokiu būdu, kiekvienas
balso požymių vektorius yra sudarytas iš balso trakto ir
žadinimo signalo požymių.
Tada vidutinis atstumas tarp tiriamojo
ir lyginamojo yra

kur ![]() yra svorio
koeficientas, nusakantis balso trakto ir sužadinimo signalo
įtaką atstumui. Jei
yra svorio
koeficientas, nusakantis balso trakto ir sužadinimo signalo
įtaką atstumui. Jei ![]() atstumas priklauso
tik nuo balso trakto, jei
atstumas priklauso
tik nuo balso trakto, jei ![]() atstumas priklauso
tik nuo žadinimo signalo, jei
atstumas priklauso
tik nuo žadinimo signalo, jei ![]() atstumui vienodą
įtaką turi ir balso traktas ir žadinimo signalas.
atstumui vienodą
įtaką turi ir balso traktas ir žadinimo signalas.
Plačiau apie šį metodą galima
pasiskaityti straipsniuose [4]- [6].
4.4.4.2 Kalbančiojo
verifikavimas
Kalbančiojo verifikavimas yra toks uždavinys, kai mes turime asmens A balso įrašus ir asmens X balso įrašą. Mums reikia atsakyti į klausimą, ar X ir A yra tas pats asmuo ar ne (3 pav.).

3. Pav. Kalbančiojo verifikavimo uždavinio
iliustracija.
Buvo sprendžiama nepriklausomo nuo
pasakyto teksto kalbančiojo verifikavimo problema. Pasiūlytas
kalbančiojo verifikavimo metodas remiasi balso intraindividualinių ir
interindividualinių iškraipymų (variacijų)
pasiskirstymų palyginimu. Intraindividualiniai iškraipymai yra žmogaus
balso variacijos tariant tą patį tekstą. Interindividualiniai
iškraipymai yra balso variacijos
skirtingiems žmonėms tariant tą patį tekstą.
Jeigu abu balso įrašai yra to paties žmogaus, tai intraindividualių iškraipymų pasiskirstymas idealiu atveju turėtų sutapti su interindividualių iškraipymų pasiskirstymu. Vadinasi, paskaičiavę šių pasiskirstymų įvertinimus - histogramas, mes galime įvertinti šių histogramų sutapimo laipsnį ir spręsti, ar tiriamasis ir lyginamasis įrašai yra pasakyti to paties žmogaus ar ne. Iškraipymų paskaičiavimui yra naudojami ir balso trakto ir balso traktą žadinančio signalo požymiai. Šie požymiai yra išskiriami iš vokalizuotų garsų pseudostacionarių intervalų.
Plačiau apie šį metodą galima
pasiskaityti straipsniuose [7]- [9].
Literatūra
1. Lipeika A., Lipeikienė J., Speaker Identification // Informatica.
1993. - Vol. 4. - No 1-2. - pp. 45-56.
2. Lipeika A., Lipeikienė J., The Use of Pseudostationary Segments for
Speaker Identification. - Proc of the 3rd European Conference on Speech
Communication and Technology, Berlin, Germany, 21-23 September, 1993. - pp.
2303-2306.
3. Lipeika A., Lipeikienė J., Speaker Identification using Vector
quantization // Informatica, 1995. - Vol. 6. - No 2, pp. 167-180.
4. Lipeika A., Šalna B., Kalbančiojo identifikavimas pagal stacionarius fonogramos segmentus// Kriminalistikos ir teismo ekspertizės problemos, Vilnius, 1996, 115-134 psl.
5. Lipeika A., and J. Lipeikienė, Recent advances in speaker identification // Proc. of the Elsnet Goes East and IMAC Workshop “Integration of Language and Speech, Moscow, 1996, pp. 97-106.
6. Lipeika A., and J. Lipeikienė, Speaker identification methods based on pseudostationary segments of voiced sounds, Informatica, 1996, Vol. 7 – No 4, 469-484.
7. Lipeika A., and J.
Lipeikienė, Speaker Recognition Based on the Use of Vocal Tract and
Residue Signal LPC Parameters//
Informatica, 1999. - Vol. 10. - No 4, pp. 449-456.
8. Lipeika A., Lipeikienė J., Kalbančiojo verifikavimas, // Konf. “Biomedicininė inžinerija” darbai, KTU, Kaunas, Technologija, 1998, 83-86 psl.
9. Lipeika A., Lipeikienė J., Kalbančiojo verifikavimo metodas besiremiantis balso trakto ir liekanos signalo požymiais// Konf. “Informacinės technologijos” pranešimų medžiaga, KTU, Kaunas, Technologija, 1999, 211-214 psl.