6. Lietuviškos lokalės (lietuvių kalbos ypatybių
informacijos technologijoje) metmenys
TURINYS
2.
Lietuviškos lokalės Nusakomoji kultūros specifikacija
3. POSIX lokalės kategorijų formalūs aprašai
4.1. LC_COLLATE kategorijos apibrėžimas
5.
Lietuviškos lokalės koduotė (charmap)
1 priedas. POSIX lokalė lietuvių kalbai
2 priedas. ISO 5589-13
lentelė
3 priedas. LST 1564 lentelė
4 priedas. LST 1590-1
lentelė (775)
5 priedas. LST 1590-2
lentelė
6 priedas. LST 1590-3
lentelė (1257)
7 priedas. LST 1590-4
lentelė
1. Lokalės
1.1. Kas yra lokalė?
Angliškas žodis „locale“ turi dvi reikšmes (pagal Webster žodyną
[1]):
1) vieta, vietovė;
2) principas, įprotis, kalbėjimo būdas.
Kalbant apie programų internacionalizaciją bei
lokalizaciją, lokalė reiškia visų nuo konkrečios vietovės (ar tai būtų šalis, ar
provincija) priklausančių dialogo su vartotoju aspektų visumą. Klaidinga manyti,
kad lokalė priklauso tik nuo kalbos – pavyzdžiui, JAV ir Jungtinės karalystės
lokalės yra skirtingos, nors vartojama ta pati kalba 2 . Taip pat negalima
sakyti, kad lokalė priklauso vien nuo šalies – pavyzdžiui, Suomijoje yra dvi
valstybinės kalbos (suomių ir švedų), tad reikia dviejų skirtingų lokalių.
1.2. Lokalės sandara
Pagal tarptautinį standartą ISO/IEC 15897:1999, Information technology
– Procedures for registration of cultural elements (kuris yra priimtas
Lietuvos standartu). gali būti
registruojami keturi kultūros specifikacijų tipai:
Nupasakojamoji kultūros specifikacija
POSIX lokalė
POSIX ženklų koduotė (Charmap)
POSIX ženklynas (Repertoiremap)
Šie tipai yra susiję tarpusavyje šitaip:
1. Nusakomoji kultūros specifikacija turi specifikuoti
kultūros normas anglų kalba, kartu gali būti pateiktos ir ekvivalenčios
specifikacijos kitomis kalbomis. Ji gali apimti klausimus, kurie nebuvo
susisteminti formaliais kultūros normų specifikavimo metodais. Jeigu
nupasakojamosios kultūros specifikacijos dalys buvo apibrėžtos taip pat ir POSIX
lokalėje arba ženklų rinkinyje, tai pastarieji turi būti nurodyti
specifikacijoje. Lietuviškosios lokalės Nusakomoji kultūros specifikacija
(lietuvių kalba) pateikta --- skyr.
2-as, 3-čias ir 4-tas tipai skirti kultūros elementų POSIX
specifikacijai, apibrėžtai ISO/IEC 9945-2.
2. POSIX lokalė pagal formalią POSIX sintaksę turi
apibūdinti kai kuriuos nusakomosios kultūros specifikacijos aspektus ir turi
nurodyti atitinkamą nupasakojamąją kultūros specifikaciją. POSIX lokalė taip pat
turi nurodyti naudojamą ženklyną ir išvardyti naudotinas POSIX ženklų koduotes.
POSIX lokalė lietuvių kalbai pateikta tolesniuose skyriuose.
3. POSIX ženklų koduotė turi apibūdinti nusakomosios
kultūros specifikacijos ar POSIX lokalės aspektus, susijusius su koduotų ženklų
rinkiniais. POSIX ženklų koduotė turi nurodyti naudojamą POSIX ženklyną, bet
gali nenurodyti , kurios POSIX lokalės ar nusakomosios kultūros specifikacijos
ją naudoja. POSX ženklų koduotė, paremta Lietuvos standartu LST ISO/IEC 8859-13,
pateikta
priede.
4. POSIX ženklynas naudojamas kaip priemonė, kuri leidžia
palaikyti POSIX lokalės arba nusakomosios kultūros specifikacijų nepriklausomumą
nuo koduotų ženklų rinkinio ir panaikina POSIX ženklų rinkinio poreikį,
registruojant POSIX lokalę. Kitų kultūros specifikacijų jis gali nenurodyti.
2. Lietuviškos lokalės Nusakomoji kultūros specifikacija
Europos lokalių registre kaupiamos nusakomoji kultūros
specifikacijos turi apibūdinti kultūros normas anglų kalba, kartu gali būti
pateiktos ir ekvivalenčios specifikacijos kitomis kalbomis. Ji gali apimti
klausimus, kurie nebuvo susisteminti formaliais kultūros normų specifikavimo
metodais. Jeigu nupasakojamosios kultūros specifikacijos dalys buvo apibrėžtos
taip pat ir POSIX lokalėje, tai turi būti nurodyta specifikacijoje.
Nusakomąją kultūros specifikaciją sudaro skirsnių rinkinys
(angl. clauses),
kurių pavadinimai yra iš anksto nustatyti. Čia pateiksime lietuviškosios lokalės
Nusakomąją kultūros specifikaciją lietuvių kalba.
1 skirsnis. Abėcėlės ženklų rikiavimo tvarka
Lietuvių kalbai būdinga abėcėlės ženklų rikiavimo tvarka
aptarta „Dabartinės lietuvių kalbos gramatikos“ (Vilnius, Mokslo ir
enciklopedijų leidykla, 1994) 17—19 psl. Norminėje lietuvių kalbos abėcėlėje iš
viso yra 32 raidės; kiekvienos jų galimi du variantai: didžioji ir mažoji.
Lietuviškosios abėcėlės raidės viena po kitos eina tokia tvarka: a ą b c č d e ę
ė f g h i į y j k l m n o p r s š t u ų ū v z ž. Jei užrašant abėcėlę
pateikiamos abejos – ir didžiosios, ir mažosios – raidės, tai paprastai jos
nurodyta seka surašomos poromis: pirma didžioji, paskui – mažoji.
Sudarant abėcėlinius sąrašus bei žodynus, žiūrima
nurodytosios abėcėlės ženklų rikiavimo eilės, tačiau paprastai lygiavertėmis
laikomos šios raidės: a = ą, e = ę = ė, i = į = y, u = ų = ū. Lygiavertėmis šiuo
atveju laikomos taip pat atitinkamos didžiosios ir mažosios raidės (jeigu sąraše
jos skiriamos).
2 skirsnis. Ženklų klasifikacija
Lietuvių kalboje skiriamos didžiosios ir mažosios raidės;
visos lietuvių abėcėlės raidės turi abu šiuos variantus. Didžiųjų ir mažųjų
raidžių vartosena reglamentuojama normatyvinių rašybos leidinių ("Dabartinės
lietuvių kalbos gramatika", 1994; "Mokomasis lietuvių kalbos rašybos ir
kirčiavimo žodynas", 1999 ir kt.).
Nelietuviškos kilmės žodžiuose, ypatingai –
asmenvardžiuose, gali pasitaikyti ir kitų alfabetų raidžių – ä, å, æ, ł, ö, ø,
q, ü, w, x ir kt. Lingvistikos darbuose ir mokomuosiuose tekstuose kai kurios
raidės (a ą e ę ė i į y j l m n o r u ų ū) gali turėti papildomus kirčio bei
priegaidės ženklus. Senuosiuose lietuviškuose raštuose taip pat apstu specifinių
rašmenų, dažniausiai – nusižiūrėtų iš anuometinės lenkų bei vokiečių rašybos.
3 skirsnis. Skaičių rašymo formatai
Skaičių rašymo lietuviškuose tekstuose tradicijos yra tam
tikru būdu susijusios su skaičius reiškiančių žodžių – skaitvardžių
specifika.
Kiekinius skaitvardžius atitinkantys (ir „pratęsiantys“)
skaičiai paprastai reiškiami pozicine dešimtaine raiškos sistema ir užrašomi
dešimčia įprastų arabiškų skaitmenų. Kitokio pagrindo pozicinės skaičių raiškos
sistemos (dvejetainė, aštuntainė, šešioliktainė ir t.t.) vartojamos palyginti
retai ir tik specifiniuose, dažniausiai techninio bei inžinerinio pobūdžio
tekstuose. Dešimtainių trupmenų skirtukas yra kablelis. Jei skaičiui užrašyti
reikia daugelio skaitmenų, jie gali būti grupuojami, pradedant nuo dešiniausiojo
(reikšiančio vienetus), po tris, ir vienas nuo kito tokie skaitmenų trejetai
(kartais vadinami „klasėmis“) atskiriami tarpeliais.
Paprastuosius kelintinius skaitvardžius atitinkantys
skaičiai gali būti reiškiami dvejopai – ir pozicine dešimtaine, ir romėniškąja
skaičių raiškos sistema. Griežtų taisyklių, nurodančių, kada vartotina viena, o
kada – kita iš tų raiškos sistemų, nėra; galima įžiūrėti tik tam tikrą daugiau
ar mažiau ryškią tradiciją (pavyzdžiui, amžiai, varžybose užimtos vietos, knygų
skyriai bene dažniau žymimi romėniškąja, o metai, valandos, puslapiai – pozicine
dešimtaine raiškos sistema išreikštais „kelintiniais“ skaičiais). Jei tokie
skaičiai reiškiami pozicine dešimtaine raiškos sistema (ir, tuo pačiu, rašomi
arabiškais skaitmenimis), tai, siekiant akivaizdžiai paliudyti „kelintinį“ jų
pobūdį, prie jų brūkšneliu gali būti prijungiamos kaitomos kelintinių
skaitvardžių galūnės -as, -a (pvz., 12-as, 45-a).
Kelintinius įvardžiuotinius skaitvardžius atitinkantys
skaičiai irgi gali būti reiškiami tiek pozicine dešimtaine, tiek ir romėniškąja
skaičių raiškos sistema, tačiau, siekiant aktualiai paliudyti jų
„įvardžiuotumą“, prie jų brūkšneliu gali būti ir dažnai būna prijungti kaitomi
(giminėmis, skaičiais bei linksniais) „įvardžiuotumo“ formantai -asis, -oji
(pavyzdžiui, XX-asis, 8-asis, 15-oji).
4 skirsnis. Pinigų sumų užrašymo formatai
Pinigų sumos lietuviškuose tekstuose paprastai užrašomos
dešimtaine pozicine skaičių raiškos sistema, arabiškais skaitmenimis. Po pinigų
sumą reiškiančio skaičiaus gali eiti atitinkamą valiutą nurodantis žodis
(reikiamu linksniu; pvz., 40 litų, 8 frankai, 60 šekelių, 2127 jenos ir pan.)
arba santrumpa. Kitų šalių valiutų santrumpos bei specifiniai žymenys ($, €, £
ir t.t.) vartojami retai, šiaipjau tik specifinio pobūdžio tekstuose, o valiutas
reiškiančios triraidės tarptautinės santrumpos (pvz., USD, GBP ir pan.) – tik
bankų skelbimuose bei dokumentuose.
Nacionalinio piniginio vieneto – lito (tarptautinis žymuo –
LTL) sutrumpinta žymėsena yra Lt, o cento – ct, ir šios santrumpos rašomos po
atitinkamą pinigų sumą reiškiančių skaičių (pvz., 115 Lt 36 ct). Centai gali
būti nurodomi ir kaip trupmeninės (šimtosios) lito dalys; dešimtainių trupmenų
skirtukas ir šiuo atveju išlieka kablelis (pvz., 115,36 Lt). Jei sumos
didelės, jas reiškiančių skaičių skaitmenis irgi galima grupuoti po tris (imant
nuo vienetus reiškiančio dešiniausio skaitmens,arba, jeigu toks yra, nuo
dešimtainių trupmenų skirtuko – kablelio); tarp šių grupių paliekama po tuščią
tarpelį (pvz., 4 212 458 163 Lt). Prireikus užrašyti neigiamą sumą, prieš ją
reiškiantį skaičių rašomas minuso ženklas (sakysim, -25,08 Lt arba -25 Lt 08
ct).
5 skirsnis. Datos ir laiko žymėjimas
Lietuviški mėnesių pavadinimai yra: „sausis“, „vasaris“,
„kovas“, „balandis“, „gegužė“, „birželis“, „liepa“, „rugpjūtis“, „rugsėjis“,
„spalis“, „lapkritis“, „gruodis“.
Lietuviški savaitės dienų pavadinimai yra: „pirmadienis“,
„antradienis“, „trečiadienis“, „ketvirtadienis“, „penktadienis“, „šeštadienis“,
„sekmadienis“.
Mėnesių ir savaitės dienų pavadinimai yra bendriniai
daiktavardžiai, todėl jiems galioja bendrosios šiai gramatinei žodžių klasei
būdingos kaitybos ir rašybos taisyklės. Nei mėnesių, nei savaitės dienų
pavadinimai paprastai netrumpinami (galimos nebent nereguliarios, atsitiktinės
santrumpos, kurių reikšmė lengvai suprantama iš konteksto); retkarčiais mėnesių
ir savaitės dienų pavadinimai keičiami jų eilės numeriais (numeruojama čia
pateikta išvardijimo tvarka).
Galimi keli tiek datos, tiek ir laiko žymėsenos tekste ar
dokumente variantai; datos užrašymai įvairuoja priklausomai nuo jų trumpinimo
būdo, o laiko – dar ir nuo norimo tikslumo.
Labiausiai išplėstas datos užrašymas būtų toks: „2002 metų
gegužės mėnesio 8 diena“. Žodis „mėnesio“ gali būti trumpinamas „mėn.“ (pvz.
„2002 metų gegužės mėn. 8 diena“), bet rišliame tekste jis dažniausiai išvis
praleidžiamas ir rašoma taip: „2002 metų gegužės 8 diena“. Taip pat norint
galima trumpinti ir žodžius „metų“ bei „diena“, pirmasis jų trumpinamas „m.“,
antrasis – „d.“; taigi, susidaro dar trys datos užrašo variantai („2002 m.
gegužės 8 diena“, „2002 metų gegužės 8 d.“ ir „2002 m. gegužės 8 d.“). Žodiniai
mėnesių pavadinimai paprastai netrumpinami, tokie jie tegalimi nebent
konspektuose ar greitraštyje. Taisyklių, aiškiau reglamentuojančių, kurį
variantą kada rinktis ir vartoti, kaip ir nėra, tai labiausiai priklauso nuo
rašančio autoriaus nuostatų, jo skonio ir nuo teksto pobūdžio bei žanro (pvz.,
oficialiuose dokumentuose bene dažniausias yra trumpiausias, paskutiniajame
pavyzdyje pateiktas variantas).
Sutrumpintai data užrašoma vien tik arabiškais
skaitmenimis, sugrupuotais į tris grupes: pirmoji, kairiausioji, būna
keturženklė skaitmenų grupė, kuri reiškia metus (paprastai – vadinamosios „mūsų
eros“, skaičiuojamos nuo Kristaus, metus), antroji, vidurinioji, būna dviženklė
ir reiškia atitinkamą mėnesį (pagal įprastą mėnesių numeraciją pradedant nuo
sausio ir baigiant gruodžiu), o paskutinioji, dešinioji, irgi yra dviženklė ir
reiškia mėnesio dieną. Viena nuo kitos šios skaitmenų grupės atskiriamos
nekeliamaisiais tarpeliais, tad visas užrašas sudaro vientisą, nedalią simbolių
grupę („žodį“). Pabrėžtina, kad „vienetiniams“ (mažesniems už 10) mėnesių ir
dienų numeriams žymėti šiuo atveju vartojami žymenys, sudaryti irgi iš dviejų
skaitmenų: kairiau nuo reikšminių vienetų skaitmenų prirašoma po nereikšminį
nulį. Tad šiuo būdu užrašyta ta pati data atrodytų taip:
„2002 05 08“.
Lietuvoje vartojama dvejopa – 24 valandų ir 12 valandų –
laiko atskaitos sistema. Aiškesnė ir universalesnė yra 24 valandų sistema.
Vartojant 12 valandų atskaitos sistemą, papildomai reikia pridėti
patikslinamuosius žodžius: „nakties“, „ryto“, „dienos“, „vakaro“.
Laikui nurodyti lietuviškuose tekstuose vartojama dvejopa
žymėsena: lietuviška (būdingesnė „normaliems“ – publicistiniams, dalykiniams,
grožiniams ir pan. – tekstams) ir tarptautinė (vartojama praktiškai tik
techniniuose ir moksliniuose tekstuose).
Vartojant lietuvišką žymėseną laikas, skaičiuojamas tik
minučių tikslumu, išplėstu būdu gali būti užrašomas taip: „4 val.
27 min.“, „11 val. 8 min.“; trumpuoju gi būdu tas pats laikas užrašomas:
„4.27 val.“, „11.08 val.“. Jei laikas skaičiuojamas sekundžių tikslumu,
paprastai jis užrašomas tik išplėstu būdu šitaip: „11 val. 8 min. 37 sek.“.
Vartojant tarptautinę žymėseną, laikas butų užrašomas: „4 h
27 min“; „11 h 8 min 37 s“.
Esant specifinėms sąlygoms (pvz., kai laikas rodomos tablo,
indikatoriuose ir pan.) ar kontekstams (pvz., kai rašoma į lentelės grafą
„Laikas“), laikas gali būti nurodomas dvitaškiu atskirtomis dviženklėmis
skaitmenų grupėmis (pvz., „11:08:37“), iš kurių pirmoji reiškia valandas,
antroji – minutes, o trečioji – sekundes. Jokiu laiko matavimo vienetu šiuo
atveju paprastai nenurodoma.
6 skirsnis. Teigiami ir neigiami atsakymai
Lietuviškas teigiamas (patvirtinamasis) atsakymas yra
„taip“, neigiamas (prieštaraujantis) – „ne“. Gestinis atsakymo „taip“ atitikmuo
yra galvos linktelėjimas žemyn, o atsakymo ne – galvos papurtymas (pasukiojimas
į šonus).
7 skirsnis. Nacionalinė ir regioninė informacijos
technologijos terminija
Oficiali nacionalinė lietuviška informacijos technologijos
terminija dar tik formuojasi; greta jos taip pat formuojasi ir specifinis
profesinis šios srities žargonas. Regioninių terminijos variantų nėra.
Svarbesnieji leidiniai, skatinantys, palaikantys ir
reguliuojantys nacionalinės terminijos, susijusios su informacijos
technologijomis, formavimąsi, yra:
Aiškinamasis kompiuterijos žodynas, Kaunas, 1995
Aiškinamasis anglų-lietuvių kalbų kompiuterijos žodynas,
Kaunas, 1977
Informatika: keturkalbis terminų žodynas, Vilnius, 1999
Lietuvos standartų serija LST ISO/IEC 2382 Informacijos
technologija. Terminai ir apibrėžimai (maždaug 25 dalys).
8 skirsnis. Nacionaliniai ir regioniniai standartų
profiliai
Lietuvos standartus tvarko Lietuvos
standartizacijos departamentas prie Vidaus reikalų ministerijos ( http://www.lsd.lt ). Atskirų šakų standartus priima technikos komitetai.
Pagrindinius informacijos technologijos standartus kuria ir priima komitetas TK
4 Informacijos
technologija. Su lietuvių kalba susijusius standartus kuria ir kiti
technikos komitetai: TK 34 Metrologija, TK 37 Terminologija.
Standartai yra kuriami Lietuvoje arba Lietuvos standartais
tampa tarptautiniai bei Europos standartai, jeigu jie išverčiami į lietuvių
kalbą ir juos priima atitinkamas standartų technikos komitetas. Rečiau vartojami
standartai gali būti priimami ir viršelio būdu – į lietuvių kalbą išvertus tik
standarto pavadinimą.
Kodavimo lentelių standartai.
LST ISO/IEC 8859-13
Lietuvos standartas LST ISO/IEC 8859-13. Informacijos
technologija. 8 bitais koduotų ženklų rinkiniai. 13 dalis. Lotynų 7-oji abėcėlė
(tapatus ISO/IEC 8859-13:1998).
Rašto ženklų kodavimą 8 bitais apibrėžia tarptautinis
standartas ISO/IEC 8859. Jį sudaro atskiros dalys, kurių kiekviena dalis
apibrėžia kodų lentelę, pritaikytą tam tikros kalbų grupės rašto ženklams
koduoti. Standartas yra atviras, t.y. gali būti papildomas naujomis dalimis.
Dabar yra 15 dalių.
Standarto 13-oji dalis ISO/IEC 8859-13 apibrėžia lotynų
7-osios abėcėlės ženklų rinkinį, turintį lietuviškus rašto ženklus. Ji išversta
į lietuvių kalbą ir priimta Lietuvos standartu, kuriam suteiktas žymuo LST
ISO/IEC 8859-13:2000. Šio standarto apibrėžta kodų lentelė kompiuteriuose žymima
trumpiau – ISO-8859-13. Tai pagrindinis Lietuvos rašto ženklų kodavimo 8 bitais
standartas ir naudotinas duomenų mainams tarp įvairių terpių (operacinių
sistemų) bei kaip pagrindas kuriant kitus kodavimo standartus.
Pasaulyje serijos ISO/IEC 8859 standartai tiesiogiai (be
pakeitimų) naudojami „Unix“ genties operacinėse sistemose (pvz. „Linux“). Dėl to
Lietuvoje šiose sistemose taikytinas standartas LST ISO/IEC 8859-13.
Standartas LST ISO/IEC 8859-13 nuo 2000 m. pakeitė iki tol
galiojusį standartą LST 1282, kuris apibrėžė kodų lentelę, vadinamą „Baltic
Rim“. Tačiau iš tikrųjų pasikeitė tik aprašymo pavidalas, o visų ženklų kodai
išliko tie patys. Lentelė pateikta priede.
LST 1564
Lietuvos standartas LST 1564. Informacijos technologija.
Ženklų kodavimas 8 bitais. Lietuviškų kirčiuotų raidžių rinkinys
Kirčiuotų raidžių standartas apibrėžia kodų lentelę, kurios
lietuviškų rašto ženklų aibė papildyta kirčiuotomis raidėmis. Šioje kodų
lentelėje pagrindinių (nekirčiuotų) lietuviškos abėcėlės raidžių ir visų kitų
ženklų, išskyrus kirčiuotas raides, kodai sutampa su standarto LST ISO/IEC
8859-13 kodais.
Šis standartas yra pagrindinis kirčiuotų raidžių
standartas. Jis tiesiogiai (be pakeitimų) vartotinas UNIX genties operacinėse
sistemose. Remiantis šiuo standartu sudaromi kirčiuotų raidžių kodavimo
standartai kitoms operacinėms sistemoms. Lentelė pateikta priede.
LST 1590
Lietuvos standartas LST 1590. Informacijos technologija.
Ženklų kodavimas 8 bitais
Šis standartas apibrėžia ženklų rinkinius, turinčius
lietuviškus rašto ženklus, ir jų kodavimą atskirose operacinėse sistemose. Jį
sudaro atskiros dalys, kurių kiekviena dalis apibrėžia kodų lentelę, skirtą tam
tikros genties operacinėms sistemoms, o taip pat atskiras dalis pagrindinei
lietuvių kalbos abėcėlei ir lietuvių kalbos abėcėlei, papildytai kirčiuotomis
raidėmis. Standartas yra atviras, t.y. gali būti papildomas naujomis dalimis.
Dabar yra 4 dalys:
LST 1590-1 Informacijos technologija. Ženklų kodavimas 8
bitais. Grafinių ženklų rinkinys DOS terpei.
Standartas apibrėžia lotynų 7-osios abėcėlės ( Latin 7 )
ženklų rinkinį (tą patį, kurį apibrėžia pagrindinis standartas LST ISO/IEC
8859-13), papildytą operacinei sistemai DOS būdingais pseudografikos ženklais 8
ir 9 stulpeliuose. Šio standarto apibrėžiamas kodavimas žinomas kodų lentelės
775 vardu. Lentelė pateikta priede.
LST 1590-2 Informacijos technologija. Ženklų kodavimas 8
bitais. Lietuviškų kirčiuotų raidžių ir fonetinių ženklų rinkinys DOS
terpei.
Kirčiuotų raidžių standartas apibrėžia kodų lentelę, kurios
lietuviškų rašto ženklų aibė papildyta kirčiuotomis raidėmis bei fonetiniais
ženklais. Šioje kodų lentelėje pagrindinių (nekirčiuotų) lietuviškos abėcėlės
raidžių ir kitų ženklų kodai sutampa su standarto LST 1590-1 kodais. Lentelė
pateikta priede.
LST 1590-3 Informacijos technologija. Ženklų kodavimas 8
bitais. Grafinių ženklų rinkinys Windows terpei.
Standartas apibrėžia lietuviškų raidžių kodavimą „Windows“
genties operacinėse sistemose (Windows 95, Windows 98, Windows 2000, Windows
NT). Jo apibrėžiama kodų lentelė kitaip žinoma 1257 vardu. Šioje lentelėje visų
lietuviškos abėcėlės raidžių kodai sutampa su standarto LST ISO/IEC 8859-13
apibrėžiamais kodais. Skiriasi tik 4 skyrybos ženklų (kabučių ir apostrofo)
kodavimas, atsiradęs dėl korporacijos „Microsoft“ savitų kodavimo principų.
Lentelė pateikta priede.
LST 1590-4. Informacijos technologija. Ženklų kodavimas 8
bitais. Lietuviškų kirčiuotų raidžių ir fonetinių ženklų rinkinys „Windows“
terpei.
Kirčiuotų raidžių standartas apibrėžia kodų lentelę, kurios
lietuviškų rašto ženklų aibė papildyta kirčiuotomis raidėmis bei fonetiniais
ženklais. Šioje kodų lentelėje pagrindinių (nekirčiuotų) lietuviškos abėcėlės
raidžių ir visų kitų ženklų, išskyrus kirčiuotas raides ir fonetinius ženklus,
kodai sutampa su standarto LST 1590-3 kodais. Lentelė pateikta priede.
LST ISO/IEC 10646-1
Lietuvos standartas LST ISO/IEC 10646-1. Universalus
keliais baitais koduotų ženklų rinkinys. 1 dalis. Sandara ir pagrindinė
daugiakalbė lentelė.
Standartas ISO/IEC 10646 apibrėžia ženklų kodavimą 32
bitais (4 baitais). Jis yra Unicode kodavimo, apibrėžiančio ženklų kodavimą 16
bitų (2 baitais), viršaibis.
Lietuvoje yra priimtas standartas ISO/IEC 10646-1 viršelio
būdu ir jam suteiktas žymuo LST ISO/IEC 10646-1.
Standarte LST ISO/IEC 10646 yra visos pagrindinės ir 33
kirčiuotos lietuviškos abėcėlės raidės. Likusias 35 kirčiuotas raides galima
išreikšti kompozicinėmis sekomis. Yra deramasi su standarto ISO/IEC 10646
kūrėjais dėl visų kirčiuotų lietuviškų raidžių tiesioginio įtraukimo į standartą
ISO/IEC 10646 bei Unicode.
Klaviatūra
LST 1582
Lietuvos standartas LST 1582:2000. Informacijos
technologija. Lietuviška kompiuterio klaviatūra. Ženklų išdėstymas. Standartas
apibrėžia galimų įvesti ženklų aibę, išdėstymą kompiuterio klaviatūroje, užrašus
ant klavišų. Ženklų aibė apima visus kodų lentelėse apibrėžtus lietuviškus rašto
ženklus. Numatyta kirčiuotų lietuviškų raidžių rinkimo galimybė.
Klaviatūros struktūra, ženklų aibė, jų išdėstymas bei
užrašai ant klavišų yra suderinti su tarptautinio klaviatūrų standarto ISO/IEC
9995 reikalavimais ir atitinka lietuviškoje raštijoje nusistovėjusias normas.
Klaviatūros pagrindinės ženklų dalies išdėstymas pateiktas priede.
LST 1285
Lietuvos standartas LST 1285:1993 Informacijos
technologija. Lietuvių kalbos ypatybės.
Šis standartas nustato raidžių rikiavimo tvarką, skaičiaus
skaitmenų skirstymo į grupes po tris skyriklį (.), trupmeninės skaičiaus dalies
skyriklį (,), datos ir laiko formatus, mėnesių ir savaitės dienų žymėjimą
kompiuteriuose.
LST ISO 8601
Lietuvos standartas LST ISO 8601:1997. Duomenų elementai ir
pasikeitimo informacija formatai. Datų ir laiko žymėjimas.
Tarptautinis standartas ISO 8601 yra išverstas į lietuvių
kalbą, priimtas Lietuvos standartu ir jam suteiktas žymuo LST ISO 8601:1997. Šis
standartas nustato laiko ir datos formatus.
Šio standarto taikymo sritis neaiški, kadangi jo nustatyti
datos ir laiko žymėjimai neatitinka žymėjimų, kuriuos apibrėžia kiti Lietuvos
standartai: raštvedyboje LST 6.1-92, informacijos technologijoje LST 1285.
Ryšium su tolesniu lietuvių kalbos informatizavimu – kalbos
analize, sinteze bei atpažinimu, o taip pat automatiniu dokumentų rengimu bei
automatiniu vertimu, reikėtų įtraukti į lokalę ir standartizuoti žymiai daugiau
lietuvių kalbos gramatikos elementų.
9 skirsnis. Ženklų rinkinio aptarimas
Įprastiniams norminės lietuvių kalbos tekstams pakanka 1
skirsnyje išvardintų dabartinės lietuvių kalbos abėcėlės raidžių.
Nelietuviškos kilmės žodžiuose, ypatingai –
asmenvardžiuose, gali pasitaikyti ir kitų alfabetų raidžių – ä, å, æ, ł, ö, ø,
q, ü, w, x ir kt.
Lingvistikos darbuose ir mokomuosiuose tekstuose, o taip
pat ir kitais atvejais, kai norima pabrėžti specifinius tarimo niuansus arba
atskirti homografus, kai kurios raidės (a ą e ę ė i į y j l m n o r u ų ū) gali
turėti viršum jų rašomus papildomus kirčio bei priegaidės ženklus.
Senuosiuose lietuviškuose raštuose taip pat apstu
specifinių rašmenų, dažniausiai – nusižiūrėtų iš anuometinės lenkų bei vokiečių
rašybos.
Užrašant tarminius tekstus ir siekiant kuo tiksliau
perteikti įvairius subtilius tarimo niuansus, yra vartojami specialūs tarminės
transkripcijos ženklai, lietuvių kalbininkų pritaikyti kaip tik lietuvių
dialektologijos reikmėms.
10 skirsnis. Rikiavimo ir paieškos taisyklės
Alfabetinio rikiavimo taisyklės, kurių laikomasi sąrašuose
bei žodynuose (vadinamosios leksikografinio rikiavimo taisyklės) plačiau
aptartos 1 skirsnyje.
Lietuviškuose tekstuose raidės kartais vartojamos ir kokių
nors išskaičiuojamų punktų ženklinimui, savotiškai jų numeracijai. Šiuo atveju
paprastai verčiamasi tik „tikromis“ lotyniškomis raidėmis, į eilę įtraukiant
taip pat ir raides q, w bei x, o specifinės lietuviškosios raidės ą, č, ę, ė, į,
š, ų, ū, ž nevartojamos, praleidžiamos. Taikoma įprastinė, tradicinė lotyniškųjų
raidžių rikiavimo tvarka (eilė). Čia – taip pat skirtinga ir didžiųjų bei mažųjų
raidžių vartosena: tos dvi raidžių atmainos leidžia realizuoti dviejų lygių
ženklinimą, tad didžiosiomis raidėmis paprastai ženklinami stambesnieji,
aukštesnio lygio punktai, o mažosiomis – jų viduje išskiriami smulkesnieji
punktai (papunkčiai). Jeigu to ar kito lygio punktų yra daugiau, negu skirtingų
ženklinimui vartojamų raidžių, tai punktams ženklinti gali būti pasitelkiamos
raidžių grupės po 2, 3 ir t.t. raides (visiškai taip pat, kaip ženklinant
stulpelius elektroninėse skaičiuoklėse, pvz., Microsoft Excel).
11 skirsnis. Ženklų transformacijos
Tam tikrais atvejais atitinkamos didžiosios raidės gali
pakeisti mažąsias ir atvirkščiai; kitaip tariant, kai kada nesilaikoma didžiųjų
ir mažųjų raidžių rašybos įprastinių normų. Paprastai tai daroma stilistiniais
sumetimais ar tiesiog siekiant didesnio grafinio raiškumo bei netikėtumo
(pavyzdžiui, vien didžiosiomis raidėmis dažnai rašomos antraštės, o vien tik
mažosios gali būti vartojamos, sakysim, plakate).
Kur kas labiau raidžių vartosena ir tarpusavio pakaita
įvairuoja istoriniuose lietuviškuose tekstuose, rašytuose tuo laiku, kai dar
nebuvo nusistovėjusi norminė rašyba.
Slaviškųjų raidynų (kirilicos) transliteravimą lietuvių
rašmenimis reglamentuoja Lietuvos standartas LST 1307 (1993 m).
12 skirsnis. Ženklų savybės
Didžiųjų raidžių rašymo taisyklės pateiktos kn.:
„Lietuvių kalbos komisijos nutarimai
1977–1998“ (Vilnius, 1998), p. 57–60;
„Mokomasis lietuvių kalbos rašybos ir
kirčiavimo žodynas“ (Kaunas, 1999), p. 31–38.
13 skirsnis. Specialiųjų ženklų vartojimas
Lietuviškuose tekstuose vartojama tik vienokia kabučių
pora: jomis išskiriamo teksto fragmento pradžioje rašoma ‹„›, o pabaigoje – ‹“›
(pvz., romanas „Žemė maitintoja“). Tarpelių tarp pačių kabučių ir jomis išskirto
teksto fragmento nepaliekama. Jeigu kabutėmis išskirtas teksto fragmentas yra
sakinio gale, kiek komplikuota tampa skyrybos ženklų vartosena: taškas rašomas
po antrųjų (uždaromųjų) kabučių, bet kiti sakinio galui būdingi skyrybos ženklai
(klaustukas, šauktukas, daugtaškis) – prieš jas.
Numerio ženklas (žodžio „numeris“ atitikmuo) lietuviškuose
tekstuose yra santrumpa „Nr.“; grotelių ženklu (#) numeris niekada nežymimas.
Tarp santrumpos „Nr.“ ir konkretų numerį nurodančių skaitmenų paliekamas tuščias
tarpelis (pvz., nr. 145, 218 nr.); tarpelis čia turėtų būti nekeliamasis – kad
santrumpa ir skaičius tekste „neperlūžtų“ į skirtingas eilutes.
Paragrafo ženklas (žodžio „paragrafas“ atitikmuo) yra
ženklas § (section sign). Dažniausiai jis vartojamas tada, kai paragrafai yra
numeruoti; tada jis eina pagret su konkrečiu paragrafo numeriu. Tarp ženklo § ir
paragrafo numerį nurodančių skaitmenų paliekamas tuščias tarpelis (pvz., § 14,
21 §); tarpelis ir čia turėtų būti nekeliamasis – kad paragrafo ženklas ir
skaičius tekste „neperlūžtų“ į skirtingas eilutes. Paragrafo ženklas yra bene
vienintelis ženklas, kuris gali būti dubliuojamas, siekiant aktualiai perteikti
žodžio „paragrafas“ daugiskaitą („paragrafai“): pvz., §§ 158–163.
Norint pabrėžti kitų objektų (pvz., puslapių, metų ir pan.)
daugiskaitą, ypač – kai konkrečiu skaičiumi nusakoma tik nurodomos jų aibės
pradžia, vartojamas sutrumpinimas „tt.“ (pvz., „žr. p. 145 tt.“).
Aritmetikos veiksmų įprastiniai ženklai yra +, –, × ir :.
Mokslinio bei techninio pobūdžio tekstuose daugyba dažnai žymima tašku, pakeltu
iki eilutės vidurio (·), o dalyba – įkypu brūkšniu (/).
14 skirsnis. Ženklų vaizdų formavimas
Lietuvių abėcėlės raidžių spausdintiniai ir rašytiniai
pavidalai pavaizduoti kn. „Mokomasis lietuvių kalbos rašybos ir kirčiavimo
žodynas“ (Kaunas, 1999), p. 4-5. Jų atkūrimo (imitavimo) tikslumas priklauso nuo
įrenginio, kuriuo tie rašmenys atkuriami, galimybių, todėl viena ir ta pati
raidė vienaip atrodys atspausdinta spaudos mašina ar didelės skiriamosios gebos
spausdintuvu, kitaip - pavaizduota menkos skiriamosios gebos įrenginiu (tarkime,
taškiniu tablo).
15 skirsnis. Ženklų įvedimas
Kompiuterio klaviatūra pritaikoma visiems dabartinės
lietuvių kalbos abėcėlės ženklams įvesti. Lietuviškų rašto ženklų išdėstymą
klaviatūroje reglamentuoja Lietuvos standartas LST 1582 (žr. 29 skirsnį).
16 skirsnis. Asmenvardžių sudarymo taisyklės
Lietuvių vyrų pavardės šiaipjau yra paveldimos: vyriškos
lyties vaikai gauna tėvo pavardę. Ypatingais atvejais (pvz., įsūniję berniuką ar
vedę berniuką turinčią moterį) vyrai gali savo pavardę suteikti taip pat ir
anksčiau kitomis pavardėmis vadintiems vaikams.
Moterų pavardės yra dvejopos: mergaičių (mergautinės) ir
ištekėjusių moterų. Mergaičių pavardės padaromos iš atitinkamos vyriškos (tėvo
ar kai kuriais atvejais – įtėvio) pavardės taip:
* Jei vyriškoji pavardė turi galūnes -as arba -a, tai
mergautinės pavardės daromos iš šios pavardės kamieno, pridedant priesagą -aitė:
Bagdonas – Bagdonaitė; Akučka – Akučkaitė.
* Jei vyriškoji pavardė turi galūnes -is, -ys , -ė arba
-ia, tai mergautinės pavardės daromos iš šios pavardės kamieno, pridedant
priesagą -ytė: Žėruolis – Žėruolytė; Balsys – Balsytė, Galaunė – Galaunytė,
Pėdnyčia – Pėdnyčytė.
* Jei vyriškoji pavardė turi galūnę -us, einančią po
kietojo priebalsio, tai mergautinės pavardės daromos iš šios pavardės kamieno,
pridedant priesagą -utė: Poškus – Poškutė, Marcinkus – Marcinkutė.
* Jei vyriškoji pavardė turi galūnes -us, einančią po j,
tai mergautinės pavardės daromos iš šios pavardės kamieno, pridedant priesagą
-ūtė: Blujus – Blujūtė. Jei ši galūnė eina po kitokio minkštojo priebalsio, tai
mergautinės pavardės padaromos su priesaga -iūtė: Kubilius – Kubiliūtė,
Vercinkevičius – Vercinkevičiūtė.
Netekėjusios moterys vadinamos mergautinėmis pavardėmis.
Norėdamos mergautines pavardes gali sau pasilikti ir ištekėjusios moterys.
Netekėjusių (ar ištekėjusių, bet pasilikusių mergautinę pavardę) moterų dukterų
pavardės sutampa su jų motinų pavardėmis; sakysim, ir motina, ir duktė tokiu
atveju būtų Vaičiūnaitė. Netekėjusių moterų sūnūs paprastai gauna pavardes,
padarytas iš motinos pavardės kamieno, pridedant atitinkamas vyriškų pavardžių
galūnes: Bagdonaitė – Bagdonas, Akučkaitė – Akučka, Žėruolytė – Žėruolis,
Balsytė – Balsys, Kubiliūtė - Kubilius ir pan. Kartais netekėjusių moterų sūnums
suteikiamos jų biologinių tėvų pavardės.
Ištekėjusių moterų pavardės paprastai padaromos iš jų vyrų
pavardžių kamienų su priesaga -ienė: Lazdauskas – Lazdauskienė, Daunys –
Daunienė, Karvelis – Karvelienė, Andiuškevičius – Andriuškevičienė, Tautkus –
Tautkienė. Jeigu vyro pavardė yra dviskiemenė ir baigiasi galūne -(i)us, kartais
, ypač – pietiniuose Lietuvos regionuose, ištekėjusių moterų pavardės daromos
pridedant priesagą -(i)uvienė: Poškus – Poškuvienė, Bliūdžius – Bliūdžiuvienė,
Sutkus – Sutkuvienė, Skardžius – Skardžiuvienė.
17 skirsnis. Kaityba
Lietuvių kalbos žodžių kaityba yra labai sudėtinga;
kaitybos modeliai ir paradigmos labai priklauso nuo to, kokiai gramatinei klasei
žodis priskirtinas. Išsamiausiai žodžių kaitybos taisyklės aprašytos „Dabartinės
lietuvių kalbos gramatikoje“ (Vilnius, 1994).
18 skirsnis. Žodžių kėlimas
Lietuvių kalbos žodžiai į kitą (tolesnę) teksto eilutę
keliami skiemenimis, todėl šiaipjau kėlimo ženklas visuomet galimas ten, kur
eina skiemenų riba (apie tai žr. „Dabartinės lietuvių kalbos gramatika“,
p. 36). Tačiau žodžių kėlimo taisyklės apskritai yra laisvesnės už skiemenų
ribų nustatymo taisykles:
* Kai tarp skiemenų susiformuoja kelių priebalsių grupė, į
kitą eilutę būtinai turi būti keliama tik paskutinioji tos grupės priebalsė, o
likusias galima ir kelti, ir palikti. Todėl, pavyzdžiui, nors skiemenų riba
žodyje „mokslas“ eina tarp „k“ ir „s“ (mok-slas), apskritai galimi tokie šio
žodžio kėlimo variantai: moks-las, mok-slas ir mo-kslas.
* Priešdėliniuose ir sudurtiniuose žodžiuose kėlimo riba
gali sutapti ir su skiemenų riba, ir su žodžio sudaromųjų dalių riba, tad irgi
atsiranda lygiaverčių kėlimo variantų (pvz., pe-lė-da ir pel-ė-da; pa-rei-ti ir
par-ei-ti); kai susiduriančios žodžio sudaromosios dalys viena baigiasi, o kita
prasideda ta pačia priebalse, žožiai keliami tik antruoju būdu, t.y. viena tokia
priebalsė paliekama, o kita – keliama į tolesnę eilutę (pvz., iš-šok-ti arba
iš-šo-kti, pus-se-se-rė ir pan.).
19 skirsnis. Rašyba
Lietuvių kalbos rašybos taisyklės kompaktiškai pateiktos
dažnokai pakartotinai leidžiamuose šiuose leidiniuose: „Lietuvių kalbos rašyba
ir skyryba“ (Valstybinė lietuvių kalbos komisija yra nutarusi norminiu laikyti
šio leidinio 1992-ųjų metų leidimą), „Mokomasis lietuvių kalbos rašybos ir
kirčiavimo žodynas“, taip pat įvairiuose mokykloms skirtuose leidiniuose.
Rašybos normas savo nutarimais įtvirtina Valstybinė lietuvių kalbos
komisija.
20 skirsnis. Numeravimas, kelintiniai skaitvardžiai bei
matų sistemos
Lietuvoje vartojama metrinė matų sistema. Svarbesnės matų
santrumpos pateiktos kn. „Mokomasis lietuvių kalbos rašybos ir kirčiavimo
žodynas“ (Kaunas, 1999) p. 41–42. Po tarptautinių matų santrumpų taškas
nerašomas, bet po lietuviškų – rašomas, todėl svarbu žiūrėti konteksto (pvz.,
vienur gali būti rašoma, tarkime, „8 h 21 min 42 s“ , o kitur – „8 val. 21 min.
42 sek.“).
Temperatūra paprastai reiškiama Celsijaus laipsniais,
tačiau specifiškuose tekstuose galimos ir kitos temperatūros reiškimo sistemos.
Po konkrečią temperatūros reikšmę nurodančio skaičiaus iškart (be tarpelio)
rašomas laipsnio ženklas (°) ir temperatūros matavimo sistemą nurodanti raidė
(Celsijaus – C, Reomiūro – R, Kelvino – K): 21°C; 312°K; 74°R.
21 skirsnis. Pinigų sumos
Žr. 4 skirsnį.
22 skirsnis. Data ir laikas
Žr. 5 skirsnį.
Dabartiniu metu Lietuvoje visus metus galioja antrosios
zonos (UTC+0200) laikas, atskiro žiemos ir vasaros laiko nėra.
23 skirsnis. Informacija apie valstybę
Oficialus lietuviškas Lietuvos valstybės pavadinimas yra
„Lietuvos Respublika“, angliškas – „Republic of Lithuania“.
Teritorijos plotas – 65200 kv. km.
24 skirsnis. Telefonų numeriai
Vieninga telefonų numerių sistema Lietuvoje dar tik
formuojasi.
Lietuvos tarptautinis telefonų numerių prefiksas yra
+370.
25 skirsnis. Pašto adresai
Pašto adresuose pirmiausia nurodomas adresatas (rašoma
naudininko linksniu, tuo pabrėžiant, kam yra skirtas laiškas ar kita siunta).
Paprastai tai būna vardu ir pavarde nurodomas asmuo, bet kai kada, ypač –
korespondencijoje, siunčiamoje į įvairias įstaigas, adresatas gali būti
nurodomas ir pareigomis. Atskirais atvejais adresatas gali būti įmonė, įstaiga
ar organizacija. Iš pagarbos asmenims, kuriems adresuojama korespondencija,
prieš adresatą gali būti rašomas jo rangą ir statusą atitinkantis titulas (taip
pat naudininko linksniu, pvz., Jo Ekscelencijai Respublikos Prezidentui;
Gerbiamajam Ponui Jonui Jonaičiui).
Tolesnė pašto adreso dalis yra vietos, kur reikia nugabenti
korespondenciją ir kur būna adresatas, nurodymas (lokalizacija). Į miestą
siunčiamai korespondencijai čia rašomas gatvės pavadinimas, namo ir buto (arba
kabineto) numeriai, aptarnaujančio pašto indeksas ir miesto vardas, o į kaimą
siunčiamai – kaimo bei aptarnaujančio pašto pavadinimas ir rajonas. Tad tipiškas
į miestą siunčiamos korespondencijos adresas atrodytų taip:
Ponui Pranui Vaičiūnui
S. Stanevičiaus g. 19–84
LT-2029 Vilnius
Tipiškas kaimo vietovėn siunčiamos korespondencijos adresas
būtų tokios struktūros:
Gerb. Pranui Vaičiūnui
Dauginių kaimas,
Kapėnų paštas,
Mažeikių rajonas
Adreso žodį „kaimas“ galima trumpinti „k.“, o „rajonas“ –
„r.“.
Jei korespondencija siunčiama iš užsienio, adresas
praplečiamas dar viena, papildoma eilute, kurioje nurodoma šalis – Lietuva.
26 skirsnis. Asmenų ir organizacijų identifikavimas
Asmenims Lietuvoje yra priskirti tam tikros struktūros
asmens kodai, sudaryti iš 11 skaitmenų.
27 skirsnis. Elektroninio pašto adresai
Kokių nors specifinių sandaros ypatumų elektroninio pašto
(e-mail) adresai Lietuvoje neturi. Paprastai gale vartojama priesaga „.lt".
28 skirsnis. Sąskaitų numeriai
Jų sandarą nustato bankų vidinės taisyklės, vieningos
sąskaitų numerių struktūros nėra.
29 skirsnis. Ženklų išdėstymas klaviatūroje
Lietuviškų rašto ženklų išdėstymą kompiuterio klaviatūroje
reglamentuoja Lietuvos standartas (LST 1582. Informacijos technologija.
Lietuviška kompiuterio klaviatūra. Ženklų išdėstymas), priimtas 2000 m.

30 skirsnis. Žmogaus ir kompiuterio dialogas
Kol kas Lietuvoje žmogaus ir kompiuterio dialogas
dažniausiai vyksta anglų kalba, nes programų, kurių interfeisas būtų išverstas į
lietuvių kalbą, dar maža.
31 skirsnis. Popieriaus lapo formatai
Plačiausiai paplitęs ir naudojamas yra A4 formato
popieriaus lapas, rečiau – A5.
32 skirsnis. Maketavimo dalykai
Lietuvos spaudiniuose dominuoja abipusis (justified) teksto
lygiavimas. Vienodinant eilučių ilgius įprasta kiek padidinti ar pamažinti
tarpus tarp žodžių, bet paprastai nekeičiami tarpeliai tarp raidžių.
3. POSIX lokalės kategorijų formalūs aprašai
POSIX lokalę sudaro tam tikrų savybių (jos vadinamos kategorijomis) aprašai. Šiame skyriuje pateikiami formalūs POSIX lokalės kategorijų aprašai. Pagal šiuos kategorijų aprašus apibrėžiamas lokalės aprašomasis failas. Kiekviena POSIX kategorija aprašomajame faile apibrėžiama vieną kartą. Kategorija apibrėžiama arba tiesiogiai arba copy direktyvos pagalba. Kategorijos neapibrėžus arba apibrėžus ją nepilnai, lokalės elgsena toje kategorijoje bus neapibrėžta.
Taip atrodo bendras struktūrinis kategorijos apibrėžimas,
taikytinas visoms kategorijoms:
[comment_char <komentarų ženklas>]
[escape_char <esc ženklas>]
# Kategorijos pradžios antraštė
<kategorijos pavadinimas>
# Kategorijos kūnas
copy <lokalės pavadinimas> | <identifikatorius> <operandas> [ ;
<operandas>]
# Kategorijos pabaigos antraštė
END <kategorijos pavadinimas>
Prieš kategorijos pradžios antraštę galime nurodyti ženklą,
skirtą komentarų žymėjimui, bei esc ženklą. Pagal nutylėjimą, komentarų ženklas
-'#', esc ženklas – '\'.
Kategorijos pavadinimas – apibrėžiamos kategorijos
pavadinimas, kuris prasideda LC_.
Lokalės pavadinimas – jau esamos lokalės, kurioje nurodyta kategorija
apibrėžta nenaudojant copy mechanizmo, pavadinimas, kategorijos kūno kopijavimo
tikslu.
Kiekvienos kategorijos kūnas sudarytas iš vienos (jei
naudojamas copy
mechanizmas) arba daugiau eilučių. Ne copy eilutę sudaro:
– identifikatorius
<identifikatorius> = <raktinis žodis> | <gretinimo elementas>
Kiekvienas raktinis žodis turi savo unikalų pavadinimą , t.y. skirtingose kategorijose negali būti naudojami tie patys raktiniai žodžiai. Raktinis žodis negali prasidėti ženklais „LC_“. Identifikatorius nuo operando atskiriamas vienu ar keliais tarpų ženklais.
– operandas(-ai)
<operandas> = <ženklas> |
"<ženklų
eilutė>"
<ženklų eilutė> = <ženklas>
<ženklas> [<ženklas>]
Ženklų eilutė apgaubiama dvigubomis kabutėmis. Jei nurodyti
keli operandai iš eilės, jie atskiriami kabliataškiais. Galimi tarpai tiek
prieš, tiek ir po kabliataškio.
Individualūs ženklai, ženklai eilutėse ir gretinimo
elementai atvaizduojami simboliniais pavadinimais. Ženklas gali būti
atvaizduojamas ir aštuonetaine, šešioliktaine, bei dešimtaine konstantomis. Jei
naudojama ne simbolinė notacija, iškyla lokalės pernešamumo tarp sistemų
problema. Norint atvaizduoti rezervuotus ženklus, prieš juos dedamas esc
ženklas.
Ženklų atvaizdavimo taisyklės:
· Ženklas atvaizduojamas simboliniu pavadinimu, apskliaustu
kampiniais skliaustais ("<>"). Apskliaustas simbolinis pavadinimas turi
atitikti simbolinį pavadinimą, apibrėžtą ženklų rinkinyje. Lokalėje nurodytas
simbolinis pavadinimas bus keičiamas į su juo susijusio ženklo reikšme iš ženklų
rinkinio. Ženklų rinkinyje neesančių simbolinių pavadinimų naudojimas bus
laikomas klaidingu, nebent tai būtų LC_CTYPE arba LC_COLLATE kategorijos(šiuo
atveju bus išduodamas perspėjimas). Simbolinio pavadinimo, dubliuojančio ženklų
rinkinyje apibrėžtą simbolinį pavadinimą, apibrėžimas collating-element
arba collating-symbol sekcijoje bus laikomas klaida.
Simboliniame pavadinime nenaudojami esc ir dešiniojo kampinio skliausto ženklai.
· Esc ženklas naudojamas prieš šiuos ženklus :
" > escape_char
norint juos atvaizduoti eilutės viduje;
, ; < > escape_char norint juos atvaizduoti eilutės išorėje.
· Ženklas gali būti atvaizduojamas aštuonetaine konstanta.
Forma:
<aštuntainė
konstanta>=<esc ženklas> <aštuntainis skaitmuo> <aštuntainis
skaitmuo> [<aštuntainis
skaitmuo>]
Kiekviena konstanta atvaizduoja baito reikšmę. Daugiabaitės reikšmės atvaizduojamos sujungtomis konstantomis, kurios išdėstytos ženklų baitų išsidėstymo tvarka, t.y. paskutinė aštuntainė konstanta atitinka paskutinį reikšminį ženklo baitą.
Pvz:
\215;\125 "\115\141\171"
· Ženklas gali būti atvaizduojamas šešioliktaine konstanta.
Forma:
<šešioliktainė
konstanta>=<escape_char><x><šešioliktainis
skaitmuo><šešioliktainis skaitmuo> [<šešioliktainis skaitmuo>]
Kiekviena konstanta atvaizduoja baito reikšmę. Daugiabaitės
reikšmės atvaizduojamos sujungtomis konstantomis, kurios išdėstytos ženklo baitų
išsidėstymo tvarka, t.y. paskutinė šešioliktainė konstanta atitinka paskutinį
reikšminį ženklo baitą.
Pvz:
\ xf5;\xe7 "\x4d\x61\x79"
· Ženklas gali būti atvaizduojamas dešimtaine konstanta.
Forma:
<dešimtainė
konstanta>=<escape_char><d><dešimtainis
skaitmuo><dešimtainis skaitmuo> [<dešimtainis skaitmuo>]
Kiekviena konstanta atvaizduoja baito reikšmę. Daugiabaitės
reikšmės atvaizduojamos sujungtomis konstantomis, kurios išdėstytos ženklo baitų
išsidėstymo tvarka, t.y. paskutinė dešimtainė konstanta atitinka paskutinį
reikšminį ženklo baitą.
Pvz:
\d99;\d231;\d99\d104 "\d77\d97\d121"
Po esc ženklo sekančios aštuonetainės, šešioliktainės ir
dešimtainės konstantos realizacijos metu pripažįstamos kaip pavienis skaičius.
Gali būti nurodomi tik koduotame ženklų rinkinyje, kuriam ir buvo sukurtas
lokalės apibrėžimas, esantys ženklai, tiek simboliniu pavadinimu, tiek pačių
atvaizdu, tiek šešioliktainėmis, aštuonetainėmis bei dešimtainėmis
konstantomis.
<ženklas>=<simbolinis
pavadinimas>|<ženklo atvaizdas>|<šešioliktainė
konstanta> | <aštuonetainė konstanta> | <dešimtainė
konstanta>
Jei nurodyta ženklų koduotė, tai tik ženklai, esantys
ženklų koduotėje gali būti nurodomi naudojant aštuonetaines, šešioliktaines ir
dešimtaines konstantas. Collating-element arba collating-symbol
sekcijoje gali būti specifikuojami simboliniai pavadinimai, neapibrėžti ženklų
koduotėje.
3.1. LC_COLLATE kategorija
3.1.1.
Paskirtis
Ši kategorija skirta ženklų arba eilučių gretinimui
aprašyti.
3.1.2.
Aprašymas
Gretinimo vienetu vadinsime gretinimo elementą, t.y. ženklą
arba ženklų seką. Lokalėje eilučių palyginimas atliekamas paženkliui,
atsižvelgiant į jų svorius. Lyginimas atliekamas, kol nerandamas skirtumas arba
nustatomas eilučių ekvivalentumas. Palyginimas gali būti atliekamas kelis
kartus, jeigu lokalėje apibrėtos daugiau nei viena gretinimo tvarka. Pavyzdžiui,
prancūzų lokalėje eilutės palyginamos naudojant pirminį svorių rinkinį. Jei
eilutės ekvivalenčios pirmoje palyginimo bazėje, jos palyginamos dar kartą,
naudojant antrinių svorių rinkinį. Elementui priskirtų svorių skaičius lygus
gretinimo tvarkų, apibrėžtų lokalėje, skaičiui.
Kiekvienas ženklas, apibrėžtas koduotės faile (arba
kiekvienas ženklas iš pernešamo ženklų rinkio, jei koduotės failas
nespecifikuotas) yra gretinamas elementas. Papildomi gretinimo elementai
apibrėžiami collating-element formuluotėje, kurios sintaksė:
collating-element character-symbol from string
LC_COLLATE kategorijoje naudojami raktiniai žodžiai:
|
copy |
Copy formuluotėje nurodomas jau esamos lokalės,
naudojamos šios kategorijos aprašymui,
pavadinimas. Jei copy formuluotė įtraukta į failą, joks kitas
raktinis žodis
negali būti nurodomas. |
|
Collating-element |
Collating-element formuluotėje nurodomi
daugiaženkliai gretinami elementai. |
Collating-element formuluotės sintaksė:
collating-element <collating-symbol> from <string>
Collating-symbol reikšme nurodomas vienas gretinimo elementas – eilutė
susidedanti iš vieno ar daugiau simbolių. collating-symbol reikšmė neturi sutapti nei su vienu
sutartiniu pavadinimu iš koduotės failo, nei su sutartiniu pavadinimu iš
gretinimo aprašo. string reikšmė – iš kelių ar daugiau ženklų susidedanti
eilutė, kuri apibrėžia collating-symbol reikšmę.
Collating-element formuluotės sintaksės pavyzdžiai:
collating-element <ch> from <c><h>
collating-element <e-acute> from <acute><e>
collating-element <11> from <1><1>
Collating-element formuluotėje apibrėžta collating-symbol
reikšmė atpažįstama tik LC_COLLATE kategorijoje.
|
collating-symbol |
Collating-symbol formuluotėje nurodomi gretinimo simboliai, naudojami
gretinimo sekos formuluotėse. |
collating-symbol formuluotės sintaksė:
collating-symbol <collating-symbol>
Collating-symbol reikšmė neturi sutapti nei su vienu sutartiniu pavadinimu
iš charmap
failo, nei su sutartiniu pavadinimu iš gretinimo aprašo.
Collating-symbol formuluotės sintaksės pavyzdžiai:
collating-symbol <UPPER_CASE>
collating-symbol <HIGH>
Collating-symbol formuluotėje apibrėžta collating-symbol
reikšmė atpažįstama tik
LC_COLLATE kategorijoje.
|
order_start |
Po order_start formuluotės turi sekti viena ar
daugiau gretinimo tvarkos formuluočių, priskiriančių gretinimo elementams
svorius. Ši formuluotė yra privaloma. |
order_start formuluotės sintaksė:
order_start <sort-rules>, <sort-rules>,...<sort-rules>
collation order statements
order_end
<sort-rules> direktyvos sintaksė:
keyword, keyword,...keyword; keyword, keyword,...keyword
Čia keyword yra vienas iš forward, backward ir position raktinių
žodžių.
Sort-rules direktyvos neprivalomos. Jei pateiktos, jos aprašo eilučių
lyginimui taikomas taisykles. Nurodytų sort-rules direktyvų skaičius nustato gretinamam
elmentui priskiriamų svorių skaičių (t.y. gretinimo tvarkų skaičių lokalėje).
Jei sort-rules
direktyvos nėra pateiktos, tariama, kad nurodytas forward raktinis
žodis. Jei direktyvos pateiktos, pirmoji sort-rules direktyva taikoma eilučių palyginime,
naudojant pirminius svorius, antroji – eilučių lyginime, naudojant antrinius
svorius, ir t.t.. Kiekvienas sort-rules direktyvų rinkinys atskiriamas ';'
(kabliataškiu). sort-rules direktyva susideda iš vieno arba kelių
raktažodžių, atskirtų kableliais. Direktyvoje naudojami šie raktiniai žodžiai:
|
Forward |
Pažymi, kad gretinimo svorių palyginimai atliekami
nuo eilutės pradžios einant iki eilutės galo. |
|
Backward |
Pažymi, kad gretinimo svorių palyginimai atliekami
nuo eilutės galo einant iki eilutės pradžios. |
|
Position |
Pažymi, kad gretinimo svorių palyginimai neliečia
specialaus simbolio IGNORE. Tai yra, jei eilutės lyginant yra lygios,
tai elementas su mažiausiu atstumu iki pradžios starto imamas
pirmuoju. |
Raktiniai žodžiai forward ir backward kartu vienoje išraiškoje nenaudojami. <sort-rules> direktyvos
sintaksės pavyzdys:
order_start forward; backward, position
Kiekvienam gretinimo elementui nebūtini operandai naudojami
pirmų, antrų arba toliau sekančių gretinimo elemento svorių apibūdinimui.
Specialiu simboliu IGNORE pažymimas gretinimo elementas, kuris turėtų būti
ignoruojamas eilučių sulyginime.
Gretinimo formuluotė su raktažodžiu ellipsis kairėje
ir collating-element-list pabaigoje-dešinėje, taikytina
kiekvienam ženklui su kodu, kuris mažėja tarp ankstesnėje formuluotėje kairėje
esančio ženklo ir sekančioje formuluotėje kairėje esančio ženklo. Jei ellipsis yra
pirmoje formuluotėje, tai interpretuojama tarytum ankstesnioje eilutėje buvo
apibrėžtas ženklas NUL. (Ženklas NUL yra ženklas, kurio visų bitų reikšmės - nulinės.)
Jei ellipsis
yra paskutinėje formuluotėje, tai interpretuojama tarytum sekančioje eilutėje
apibrėžiama didžiausio kodo reikšmė.
Raktinis žodis ellipsis esąs collating-element-list vietoje, nurodo priskiriamus
svorius ženklams nustatytoje eilėje, skaitmeniškai didėjančia tvarka pradedant
nuo ankstesnės formuluotės kairėje esančio ženklo simbolio svorio.
Pastaba: Raktinio žodžio ellipsis naudojimas išplaukia iš lokalės galimybės skirtingai gretinti, t.y. priklausomai nuo su ja kompiliuojamų ženklų rinkinius aprašančių kuoduočių failų..
Visi ženklų rinkinyje esantys ženklai privalo būti
išdėstyti tiksliai pagal gretinimo tvarką arba besąlygiškai, naudojant specialų
simbolį UNDEFINED. Specialus simbolis UNDEFINED apima
visas koduojamų ženklų rinkinio reikšmes, kurios nebuvo tiksliai apibrėžtos arba
buvo su ellipsis simboliu. Į gretinimo tvarką šie ženklai įtraukiami punkte,
pažymėtame specialiu simboliu UNDEFINED ir išdėstomi pagal ženklų kodų reikšmes
rinkinyje. Jeigu specialaus simbolio UNDEFINED nėra ir ne visi gretinimo elementai iš
koduojamų ženklų rinkinio yra apibrėžti pagal gretinimo tvarką, išduodamas
perspėjimas ir visi neapibrėžti ženklai išdėstomi ženklų gretinimo tvarkos
gale.
Lokalės LC_COLLATE kategorijos gretinimo tvarkos formuluotės
pavyzdys:
order_start forward;backward
UNDEFINED IGNORE;IGNORE
<LOW>
<LOW>;<space>
...
<LOW>;...
<a>
<a>;<a>
<a-acute> <a>;<a-acute>
<a-grave> <a>;<a-grave>
<A>
<a>;<A>
<A-acute> <a>;<A-acute>
<A-grave> <a>;<A-grave>
<ch>
<ch>;<ch>
<Ch>
<ch>;<Ch>
<s>
<s>;<s>
<ss>
<s><s>;<s><s>
<eszet> <s><s>;<eszet><eszet>
...
<HIGH>;...
<HIGH>
order_end
Šio pavyzdžio interpretacija yra tokia:
· Specialus simbolis UNDEFINED nurodo, kad visi ženklai, kurie nebuvo
nurodyti apibrėžime (tiek tiksliai, tiek su simboliu ellipsis) yra ignoruojami
gretinant.
· Visi gretinami elementai tarp <space> ir <a>, pirmuoju svoriu turi tą pačią
ekvivalentumo klasę ir antruoju – svorius, pagal jų koduojamų ženklų rinkinio
reikšmes.
· Ženklo didžioji ir mažoji formos priklauso tai pačiai
pirmąjai ekvivalentumo klasei.
· Daugiaženklis gretinimo elementas <c><h> atvaizduojamas gretinimo
simboliu <ch> ir priklauso tai pačiai
ekvivalentumo klasei kaip ir daugiaženklis gretinimo elementas <C><h>.
· Ženklas <eszet> gretinamas kaip <s><s> eilutė, t.y. prieš
palyginimą vienas ženklas <eszet> išplečiamas į du ženklus.
3.2. LC_CTYPE kategorija
3.2.1.
Paskirtis
Skirta ženklų klasifikacijos, konvertavimo ir kitų ženklų
atributų aprašymui.
3.2.2.
Aprašymas
LC_CTYPE kategorija lokalės aprašomajame faile apibrėžia ženklų klasifikaciją, didžiųjų/mažųjų raidžių konvertavimą, bei kitus ženklų atributus.
Visi LC_CTYPE kategorijos formuluočių operandai apibrėžiami
kaip ženklų sąrašai. Kiekvienas sąrašas susideda iš vieno ar daugiau
kabliataškiu atskirtų ženklų arba sutartinių (simbolinių) ženklų pavadinimų.
Tolesniuose šios kategorijos aprašuose terminas automatiškai
įtraukiami reiškia, kad klaidos nebus, nepriklausomai ar nurodomi ženklai
įtraukiami ar praleidžiami. Jei ženklai nenurodyti – jie bus suteikiami, jei
nurodyti – jie bus priimti.
|
copy |
Copy formuluotėje nurodomas jau esamos lokalės,
naudojamos šios kategorijos aprašymui, pavadinimas. Jei copy
formuluotė įtraukta į failą, joks kitas raktinis žodis negali būti
nurodomas. |
|
Upper |
Apibrėžia didžiąsias raides. Ženklai, apibrėžti cntrl, digit, punct arba space
raktažodžiais, negali būti nurodyti. Mažiausiai, turi būti apibrėžtos A-Z
didžiosios raidės. |
|
Lower |
Apibrėžia mažąsias raides. Ženklai, apibrėžti cntrl, digit, punct arba space
raktažodžiais, negali būti nurodyti. Mažiausiai, turi būti apibrėžtos a-z
mažosios raidės. |
|
Alpha |
Apibrėžia visų raidžių ženklus. Ženklai, apibrėžti cntrl, digit, punct arba space
raktažodžiais, negali būti nurodyti. Ženklai, apibrėžti upper ir lower
raktažodžiais, automatiškai įtraukiami į šią ženklų klasę. |
|
Digit |
Apibrėžiami ženklai, atvaizduojantys skaitmenis. Gali
būti nurodyti tik skaitmenys 0, 1, 2, 3, 4, 5, 6, 7, 8, 9. |
|
Alnum |
Apibrėžia raidinius ir skaitinius ženklus. Ženklai,
apibrėžti cntrl, punct, or space raktažodžiais, negali būti nurodyti.
Ženklai, apibrėžti alpha ir digit raktažodžiais, automatiškai įtraukiami į
šią ženklų klasę. |
|
Space |
Defines whitespace characters. No character defined
by the upper, lower, alpha, digit, graph, cntrl, or xdigit keyword can be specified. At a minimum,
the <space> , <form-feed> , <newline> , <carriage return> , <tab> , and <vertical-tab> characters, and
any characters defined by the blank keyword, must be specified. |
|
Cntrl |
Apibrėžia valdymo ženklus. Ženklai, apibrėžti upper, lower, alpha, digit, punct, graph, print, xdigit ir space
raktažodžiais, negali būti nurodomi. |
|
Punct |
Apibrėžia skyrybos ženklus. Ženklas, nurodytas kaip
<space> ženklas ir
ženklai,apibrėžti upper, lower, alpha, digit, cntrl ir xdigit raktažodžiais, negali būti nurodomi. |
|
Graph |
Apibrėžia spausdintinus ženklus, neįtraukiant <space> ženklo. Jei šis
raktažodis nėra nurodytas, ženklai, apibrėžti upper, lower, alpha, digit, xdigit ir punct
raktažodžiais automatiškai įtraukiami į šią ženklų klasę. Ženklai,
apibrėžti cntrl raktažodžiu, negali būti nurodomi. |
|
Print |
Apibrėžia spausdintinus ženklus, įtraukiant <space> ženklą. Jei šis
raktažodis nėra nurodytas, ženklas <space> ir ženklai, apibrėžti upper, lower, alpha, digit, xdigit ir punct
raktažodžiais, automatiškai įtraukiami į šią ženklų klasę. Ženklas,
apibrėžtas cntrl raktažodžiu negali būti nurodytas. |
|
Xdigit |
Apibrėžia šešioliktainius skaitmenis. Gali būti
nurodomi skaitmenys 0-9, raidės A-F ir raidės a-f. xdigit
keyword defaults to its normal class limits. |
|
Blank |
Apibrėžia (blank) tuščius ženklus. Jei šis raktažodis
nenurodytas, <space> ir <horizontal-tab> ženklai yra
įtraukiami į šią ženklų klasę. Visi ženklai, apibrėžti šioje formuluotėje,
automatiškai įtraukiami į space raktažodžio klasę. |
|
Charclass |
Apibrėžia vieną ar kelis lokalės specifinių ženklų
klasių pavadinimus, atskirtų kabliataškiu eilučių pavidalu. Kiekviena iš
išvardintų ženklų klasių gali būti apibrėžta LC_CTYPE apibrėžime vėliau.
Ženklų klasės vardas susideda mažiausiai - iš vieno ir daugiausiai - iš 32
baitų raidinių ar skaitinių ženklų iš nešiojamo ženklų rinkinio. Pirmas
ženklų klasės vardo ženklas negali būti skaitmuo. Vardas negali lygti nė
vienam LC_CTYPE raktažodžiui, apibrėžtam šioje sekcijoje. |
|
Charclass-name |
Apibrėžia ženklus, klasifikuojamus kaip
priklausančius išvardintoms lokalės specifinių ženklų klasėms. POSIX
lokalėje neturi būti lokalės specifinėmis vadinamų ženklų klasių. Jei klasės vardas apibrėžtas charclass
raktažodžiu, bet vėliau vardui nėra priskiriamas nė vienas ženklas, tuomet
šis vardas atstovauja klasei, kuriai nepriklauso nė vienas ženklas. Charclass-name gali būti naudojamas kaip Property
parametras wctype paprogramėje ir tr
komandoje. |
|
Toupper |
Apibrėžia ženklų keitimą iš mažųjų raidžių į
didžiąsias raides. Šio raktažodžio operandai susideda iš kabliataškiu
atskirtų ženklų porų. Kiekviena ženklų pora apskliaudžiama '(' ir ')'
(lenktiniais skliaustais) ir nuo kitos poros atskiriama ',' (kableliu).
Pirmas ženklas poroje – mažoji raidė, antras – didžioji. Nurodyti gali
būti tik tie ženklai, kurie buvo apibrėžti lower ir upper
raktažodžiais. |
|
Tolower |
Apibrėžia ženklų keitimą iš didžiųjų raidžių į
mažąsias raides. Šio raktažodžio operandai susideda iš kabliataškiu
atskirtų ženklų porų. Kiekviena ženklų pora apskliaudžiama ( )
(lenktiniais skliaustais) ir nuo kitos poros atskiriama , (kableliu).
Pirmas ženklas poroje – didžioji raidė, antras – mažoji. Nurodyti gali
būti tik tie ženklai, kurie buvo apibrėžti lower ir upper
raktažodžiais. |
Tolower raktinis žodis neprivalomas. Jei jis nenurodytas, keitimas
nustatomas atvirkštiniu toupper raktažodžiui, jei jis apibrėžtas. Jei abu, toupper ir tolower,
raktažodžiai nėra apibrėžti, keitimas nustatomas kaip ir C lokalėje.
LC_CTYPE kategorijoje nėra palaikomi daugiaženkliai
elementai. Pavyzdžiui, vokiečių sharp-s ženklas tradiciškai klasifikuojamas kaip
mažoji raidė. Šį ženklą atitinkančios didžiosios raidės nėra, todėl verčiant
vokišką tekstą į didžiąsias raides, sharp-s ženklas keičiamas į du ženklus ss.
Šios rūšies perkeitimai neįeina į raktažodžių toupper ir tolower apibrėžimo
sritį.
Šiais raktiniais žodžiais apibrėžtų ženklų klasių tarpusavio galimas kombinacijas atvaizduoja 1 lentelė:
1 lentelė. Galimos klasių tarpusavio kombinacijos
|
|
Gali taip pat priklausyti | ||||||||||
|
Klasė |
upper |
Lower |
Alpha |
Digit |
space |
cntrl |
Punct |
graph |
print |
xdigit |
blank |
|
Upper |
|
- |
A |
x |
x |
x |
X |
A |
A |
- |
x |
|
Lower |
- |
|
A |
x |
x |
x |
X |
A |
A |
- |
x |
|
Alpha |
- |
- |
|
x |
x |
x |
X |
A |
A |
- |
x |
|
Digit |
x |
X |
x |
|
x |
x |
X |
A |
A |
A |
x |
|
Space |
x |
X |
x |
x |
|
- |
* |
* |
* |
x |
- |
|
Cntrl |
x |
X |
x |
x |
- |
|
X |
x |
x |
x |
- |
|
Punct |
x |
X |
x |
x |
- |
x |
|
A |
A |
x |
- |
|
Graph |
- |
- |
- |
- |
- |
x |
- |
|
A |
- |
- |
|
Print |
- |
- |
- |
- |
- |
x |
- |
- |
|
- |
- |
|
Xdigit |
- |
- |
- |
- |
x |
x |
X |
A |
A |
|
x |
|
Blank |
x |
X |
x |
X |
A |
- |
* |
* |
* |
x |
|
'A' - automatiškai įtraukiama (žr.tekstą
aukščiau);
'-' – leidžiama įtraukti;
'x' – abipusiškai nesuderinamos;
'*' – tarpo ženklas, kuris priklauso space ir blank klasėms, negali priklausyti punct arba graph, bet automatiškai įtraukiamas į print klasę. Kiti space ir blank klasėms priklausantys ženklai gali būti klasifikuojami taip pat ir punct, graph arba print klasėse.
3.3. LC_NUMERIC kategorija
3.3.1.
Paskirtis
Ši kategorija skirta skaičių (kurie nėra pinigų sumos),
atvaizdavimui aprašyti.
3.3.2.
Aprašymas
Visi LC_NUMERIC kategorijos raktinių žodžių operandai –
eilutės arba sveiki skaičiai. Eilutės apgaubiamos " " (paprastomis kabutėmis).
Visos reikšmės nuo raktinių žodžių atskiriamos vienu arba daugiau tarpų. Dvejos
gretimos kabutės " " pažymi neapibrėžtą eilutės reikšmę. Skaičius –1 pažymi
neapibrėžtą sveikojo skaičiaus reikšmę. LC_NUMERIC kategorijos raktiniai žodžiai:
|
copy |
Nurodomas jau esamos lokalės, naudojamos šios
kategorijos aprašymui, pavadinimas. Jei copy
formuluotė įtraukta į failą, joks kitas raktinis žodis negali būti
nurodomas. |
|
decimal_point |
Nurodoma eilutė, naudojama dešimtųjų dalių atskyrimui
trupmenoje, ne piniginių skaitmeninių dydžių formatavime. |
|
thousands_sep |
Nurodoma eilutė – skirtukas, naudojamas skaitmenų
grupavimui į kairę nuo dešimtųjų dalių skyrėjo, sudarytuose skaitiniuose
ne piniginiuose dydžiuose. |
|
grouping |
Apibrėžiamas kiekvienos skaitmenų grupės dydis
suformuotuose ne piniginiuose dydžiuose. Raktinio žodžio grouping
operandas susideda iš sveikųjų skaičių, atskirtų kabliataškiais, sekos.
Kiekvienas sveikas skaičius nurodo skaitmenų skaičių grupėje. Pirmasis
sveikas skaičius apibrėžia grupės, esančios tuoj pat po dešimtųjų dalių
skyriklio į kairę, dydį. Toliau esantys sveikieji skaičiai apibrėžia
sekančias grupes, esančias ankstesnės grupės kairėje pusėje. Jei
paskutinis sveikas skaičius nėra –1, ankstesnės grupės dydis pakartotinai
naudojamas grupuojant likusius skaitmenis. Jeigu paskutinis sveikas
skaičius –1, likusieji skaitmenys nebegrupuojami. |
Grouping formuluotės interpretacijos pavyzdys:
Tarkime, formatuojama reikšmė yra 123456789 ir thousands_sep
raktažodžio operandas yra '(viengubos kabutės), tai rezultatas būtų
toks:
|
Grouping Value |
Formatted Value |
|
3;-1 |
123456'789 |
|
3 |
123'456'789 |
|
3;2;-1 |
1234'56'789 |
|
3;2 |
12'34'56'789 |
|
-1 |
123456789 |
3.4. LC_MONETARY kategorija
3.4.1.
Paskirtis
Ši kategorija skirta pinigų sumų vaizdavimo aprašymui.
3.4.2.
Aprašymas
Visi LC_MONETARY kategorijos raktinių žodžių operandai
eilutės arba sveikieji skaičiai. Visi operandai nuo apibrėžiamų raktažodžių
atskiriami vienu arba daugiau tarpų. Dvi gretimos paprastos kabutės
( "" ) žymi neapibrėžtą eilutės reikšmę. Skaičius –1 žymi neapibrėžtą
sveikojo skaičiaus reikšmę.
|
copy |
Copy formuluotėje nurodomas jau esamos lokalės,
naudojamos šios kategorijos aprašymui, pavadinimas. Jei copy
formuluotė įtraukta į failą, joks kitas raktinis žodis negali būti
nurodomas. |
|
int_curr_symbol |
Nurodoma eilutė – tarptautinis valiutos pavadinimas.
Int_curr_symbol raktažodžio operandas yra
keturženklė eilutė. Ketvirtasis ženklas – skirtukas tarp tarptautinio
valiutos pavadinimo ir pinigų sumos. |
|
currency_symbol |
Nurodo eilutę – vietinį valiutos pavadinimą. |
|
mon_decimal_point |
Nurodo eilutę, naudojamą pinigų sumose dešimtainių
dalių skirtukui užrašyti. |
|
mon_thousands_sep |
Nurodo ženklą skirtuką, naudojamą skaitmenų į kairę
nuo dešimtainio kablelio grupavimui pinigų sumose. |
|
mon_grouping |
Nurodo eilutę, kuri apibrėžia kiekvienos skaitmenų
grupės dydį. Mon_grouping raktažodžio operandas – sveikųjų
skaičių, atskirtų kabliataškiais, seka. Kiekvienas sveikas skaičius nurodo
grupėje esančių skaitmenų skaičių. Pirmas sveikas skaičius apibrėžia
grupės dydį, esančios kairėje iš karto po dešimtainio kablelio. Sekantys
sveikieji skaičiai apibrėžia prieš tai apibrėžtų grupių kairėje esančių
grupių dydžius. Jei paskutinis sekos skaičius ne –1, ankstesnės grupės
dydis pakartotinai naudojamas likusių skaitmenų grupavimui. Jei paskutinis
sekos skaičius –1, likusieji skaitmenys negrupuojami. |
|
positive_sign |
Nurodo eilutę, naudojamą neneigiamoms pinigų sumoms
žymėti. |
|
negative_sign |
Nurodo eilutę, naudojamą neigiamoms pinigų sumoms
žymėti. |
|
int_frac_digits |
Nurodo sveikąjį skaičių, kuris apibrėžia po
dešimtainio kablelio išvedamų skaičių kiekį su int_curr_symbol
reikšme suformuotose pinigų sumose . |
|
frac_digits |
Nurodo sveikąjį skaičių, kuris apibrėžia po
dešimtainio kablelio išvedamų skaičių kiekį su currency_symbol
reikšme suformuotose pinigų sumose . |
|
p_cs_precedes |
Nurodo sveiką skaičių (0 arba 1), žymintį ar int_curr_symbol
ir
currency_symbol eilutės rašomos už ar prieš neneigiamas pinigų sumas. 0
Žymi, kad valiutos pavadinimas rašomas už neneigiamos
pinigų sumos. 1
Žymi, kad valiutos pavadinimas rašomas prieš
neneigiamą pinigų sumą. |
|
p_sep_by_space |
Nurodo sveiką skaičių (0, 1 arba 2), žymintį ar int_curr_symbol
ir
currency_symbol eilutės atskiriamos tarpu nuo neneigiamų pinigų
sumų. 0 Žymi, kad tarpas neskiria valiutos pavadinimo ir pinigų sumos. 1
Žymi, kad tarpas skiria valiutos pavadinimą ir pinigų
sumą. 2
Žymi, kad tarpas atskiria valiutos pavadinimą ir positive_sign eilutę, jei jie gretimi. |
|
n_cs_precedes |
Nurodo sveiką skaičių (0 arba 1), žymintį ar int_curr_symbol
ir
currency_symbol eilutės rašomos už ar prieš neigiamas pinigų sumas. 0
Žymi, kad valiutos pavadinimas rašomas už neigiamos
pinigų sumos. 1
Žymi, kad valiutos pavadinimas rašomas prieš neigiamą
pinigų sumą. |
|
n_sep_by_space |
Nurodo sveiką skaičių (0, 1 arba 2), žymintį ar int_curr_symbol
ir
currency_symbol eilutės atskiriamos tarpu nuo neigiamų pinigų
sumų. 0
Žymi, kad tarpas neskiria valiutos pavadinimo ir
pinigų sumos. 1
Žymi, kad tarpas skiria valiutos pavadinimą ir pinigų
sumą. 2
Žymi, kad tarpas atskiria valiutos pavadinimą ir negative_sign eilutę, jei jie gretimi. |
|
p_sign_posn |
Nurodo sveiką skaičių (0,1, 2, 3 arba 4), žymintį positive_sign eilutės vietą neneigiamose pinigų
sumose. 0
Žymi, kad left_parenthesis ir right_parethesis simboliai gaubia pinigų sumą ir
eilutę int_curr_symbol arba
currency_symbol. 1
Žymi, kad positive_sign eilutės vieta yra prieš sumą ir int_curr_symbol
arba
currency_symbol. 2
Žymi, kad positive_sign eilutės vieta yra už sumos ir int_curr_symbol arba currency_symbol. 3
Žymi, kad positive_sign eilutės vieta yra prieš pat int_curr_symbol arba currency_symbol. 4
Žymi, kad positive_sign eilutės vieta yra iš karto už int_curr_symbol arba currency_symbol. |
|
n_sign_posn |
Nurodo sveiką skaičių (0,1, 2, 3 arba 4), žymintį negative_sign eilutės vietą neneigiamose pinigų
sumose. 0
Žymi, kad left_parenthesis ir right_parethesis simboliai gaubia pinigų sumą ir
eilutę int_curr_symbol arba
currency_symbol. 1
Žymi, kad negative_sign eilutės vieta yra prieš sumą ir int_curr_symbol
arba
currency_symbol. 2
Žymi, kad negative_sign eilutės vieta yra už sumos ir int_curr_symbol arba currency_symbol. 3
Žymi, kad negative_sign eilutės vieta yra prieš pat int_curr_symbol arba currency_symbol. 4
Žymi, kad negative_sign eilutės vieta yra iš karto už int_curr_symbol arba currency_symbol. |
|
debit_sign |
Nurodo eilutę – debeto simbolį (DB)
neneigiamoms pinigų sumoms žymėti. |
|
credit_sign |
Nurodo eilutę – kredito simbolį (CR)
neigiamoms pinigų sumoms žymėti. |
|
left_parenthesis |
Nurodo ženklą, ekvivalentų ( (kairiąjam skliaustui),
naudojamą p_sign_posn ir n_sign_posn
formuluotėse pinigų sumai ir valiutos pavadinimui apskliausti. |
|
right_parenthesis |
Nurodo ženklą, ekvivalentų ) (dešniąjam skliaustui),
naudojamą p_sign_posn ir n_sign_posn
formuluotėse pinigų sumai ir valiutos pavadinimui apskliausti. |
Pakeitus vienos formuluotės reikšmes galime gauti unikalų
pinigų sumų formatą. Pavyzdžiui:
2 lentelėje pavaizduoti įvairių kombinacijų rezultatai,
naudojant skirtingas p_cs_precedes, p_sep_by_space ir p_sign_posn
reikšmes:
2 lentelė. P_cs_precedes, p_sep_by_space ir p_sign_posn laukų
su skirtingomis reikšmėmis galimų
kombinacijų pavyzdys.
|
p_cs_precedes |
p_sign_posn |
p_sep_by_space = | ||
|
|
|
2 |
1 |
0 |
|
p_cs_precedes =1 |
p_sign_posn=0 |
($1.25) |
($ 1.25) |
($1.25) |
|
|
p_sign_posn=1 |
+ $1.25 |
+$ 1.25 |
+$1.25 |
|
|
p_sign_posn=2 |
$1.25 + |
$ 1.25+ |
$1.25+ |
|
|
p_sign_posn=3 |
+ $1.25 |
+$ 1.25 |
+$1.25 |
|
|
p_sign_posn=4 |
$ +1.25 |
$+ 1.25 |
$+1.25 |
|
p_cs_precedes =2 |
p_sign_posn=0 |
(1.25 $) |
(1.25 $) |
(1.25$) |
|
|
p_sign_posn=1 |
+1.25 $ |
+1.25 $ |
+1.25$ |
|
|
p_sign_posn=2 |
1.25$ + |
1.25 $+ |
1.25$+ |
|
|
p_sign_posn=3 |
1.25+ $ |
1.25 +$ |
1.25+$ |
|
|
p_sign_posn=4 |
1.25$ + |
1.25 $+ |
1.25$+ |
3.5. LC_TIME kategorija
3.5.1.
Paskirtis
Ši kategorija skirta datos ir laiko atvaizdavimo
aprašymui.
3.5.2.
Aprašymas
Visi LC_TIME kategorijos raktažodžių operandai eilutės arba
sveikieji skaičiai. Raktiniai žodžiai nuo operandų atskiriami vienu arba daugiau
tarpų. Dvejos gretimos paprastos kabutės " " pažymi neapibrėžtą eilutės reikšmę.
Skaičius –1 pažymi neapibrėžtą sveikojo skaičiaus reikšmę. LC_TIME
kategorijos raktiniai žodžiai:
|
copy |
copy formuluotėje nurodomas jau esamos lokalės,
naudojamos šios kategorijos aprašymui, pavadinimas. Jei copy
formuluotė įtraukta į failą, joks kitas raktinis žodis negali būti
nurodomas. | |
|
abday |
Apibrėžia savaitės dienų pavadinimų santraupas, pagal
lauko %a deskriptorių. Atpažįstamos reikšmės
susideda iš 7 kabliataškiais atskirtų eilučių. Visos eilutės privalo būti
vienodo ilgio ir susidėti iš penkių arba mažiau ženklų. Pirmoji eilutė
atitinka pirmos savaitės dienos (Sunday) sutrumpintą pavadinimą (Sun),
antroji – antros savaitės dienos pavadinimo sutrumpinimą, ir t.t.. | |
|
day |
Apibrėžia pilnus savaitės dienų pavadinimus, pagal
lauko %A deskriptorių. Atpažįstamos reikšmės
susideda iš 7 kabliataškiais atskirtų eilučių. Pirmoji eilutė atitinka
pirmos savaitės dienos (Sunday) pilną pavadinimą , antroji – antros
savaitės dienos pilną pavadinimą, ir t.t.. | |
|
abmon |
Apibrėžia mėnesių pavadinimų santrumpas pagal lauko
%b deskriptorių. Atpažįstamos reikšmės
susideda iš 12 kabliataškiais atskirtų eilučių. Visos eilutės privalo būti
vienodo ilgio ir susidėti iš penkių arba mažiau ženklų. Pirmoji eilutė
atitinka pirmojo metų mėnesio sutrumpintą pavadinimą, antroji – antrojo
mėnesio sutrumpintą pavadinimą, ir t.t... | |
|
mon |
Apibrėžia pilnus mėnesių pavadinimus pagal lauko
%B deskriptorių. Atpažįstamos reikšmės
susideda iš 12 kabliataškiais atskirtų eilučių. Pirmoji eilutė atitinka
pirmojo metų mėnesio pilną pavadinimą, antroji – antrojo mėnesio pilną
pavadinimą, ir t.t.. | |
|
d_t_fmt |
Apibrėžia eilutę, naudojamą standartiniam datos ir
laiko užrašymui pagal lauko %c deskriptorių. Eilutėje gali būti bet
kokios ženklų ir laukų deskriptorių kombinacijos. | |
|
d_fmt |
Apibrėžia eilutę, naudojamą standartinės datos
užrašymui pagal lauko %x deskriptorių. Eilutėje gali būti bet
kokios ženklų ir laukų deskriptorių kombinacijos. | |
|
t_fmt |
Apibrėžia eilutę, naudojamą standartiniam laiko
užrašymui pagal lauko %X deskriptorių. Eilutėje gali būti bet
kokios ženklų ir laukų deskriptorių kombinacijos. | |
|
am_pm |
Apibrėžia eilutes, atvaizduojančias sąvokas ante meridiem
(prieš pietus) ir post meridiem (po pietų) pagal lauko %p deskriptorių. Atpažįstamos reikšmės
susideda iš dviejų, kabliataškiu atskirtų eilučių. Pirma eilutė atitinka
ante
meridiem požymį, antra – post meridiem požymį. | |
|
t_fmt_ampm |
Apibrėžia eilutę, standartiniam 12 valandų laikui
užrašyti, įskaitant am_pm reikšmę (lauko %p deskriptorius). Ši formuluotė
atitinka lauko %r deskriptorių. Eilutėje gali būti bet
kokios ženklų ir lauko deskriptorių kombinacijos. | |
|
era |
Apibrėžia metų skaičiavimą ir atvaizdavimą lokalėje
kiekvienai erai (imperatoriaus viešpatavimui), pagal lauko %E deskriptoriaus modifikatorių.
Kiekvienai erai apibūdinti privalo būti viena eilutė, tokiu formatu: Direction:offset:start_date:end_date:name:format Eros eilutės formato kintamieji: | |
|
direction |
Pažymi – (minuso) arba + (pliuso) ženklą. Pliuso
ženklas nurodo, kad skaičiuojant nuo pradinės iki galinės datos, metai
keičiasi didėjančia tvarka. Minuso ženklas nurodo, kad skaičiuojant nuo
pradinės iki galinės datos, metai keičiasi mažėjančia tvarka. | |
|
Offset |
Pažymi skaičius, reiškiantis pirmus eros metus. | |
|
Start_date |
Pažymi eros pradžios datą yyyy/mm/dd forma,
kurioje yyyy, mm ir dd yra metai, mėnuo ir diena, atitinkamai.
Ankstesni už ME 1 metus, metai atvaizduojami neigiamais skaičiais.
Pavyzdžiui, era, prasidedanti 50 metais PME gegužės 7 dieną bus
atvaizduota: –50/05/07 . | |
|
End_date |
Pažymi eros pabaigos datą. Forma ta pati, kaip ir
kintamojo start_date arba viena iš dviejų specialių
reikšmių –* arba +*. Reikšmė –* pažymi,
kad eros galinė data tęsiama atgal, į laiko pradžią. Reikšmė +* pažymi,
kad eros galinė data tęsiama pirmyn į laiko pabaigą. Dėl to,
chronologiškai, galinė data gali būti prieš arba po eros pradinės datos.
Pavyzdžiui, eilutės, žyminčios laikotarpius „prieš mūsų erą“ (PME) ir
„mūsų eros“ (ME) įvedamos taip: +:0:0000/01/01:+*:PME:%o %N +:1:-0001/12/31:-*:ME:%o %N | |
|
Name |
Pažymi eilutę, reiškiančią eros pavadinimą, kuri yra
pakeičiama lauko %N deskriptoriuje field descriptor. | |
|
Format |
Pažymi eilutę, lauko %E deskriptoriaus formatavimui.
Paprastai ši eilutė yra laukų %o ir %N deskriptorių funkcija. | |
|
era reikšmė susideda iš eilučių, kur viena eilutė skirta
vienai erai aprašyti. Jei aprašoma daugiau nei viena era, kiekvienos eros
eilutė atskirta ; (kabliataškiu). | ||
|
era_year |
Apibrėžia eilutę, naudojamą metams užrašyti
alternatyviame eros formate, pagal lauko %Ey deskriptorių. Eilutėje gali būti
bet kokios ženklų ir lauko deskriptorių kombinacijos. | |
|
Era_d_fmt |
Apibrėžia eilutę, naudojamą datos atvaizdavime
alternatyviame eros formate, pagal lauko %Ex deskriptorių. Eilutė gali susidėti
iš bet kokios ženklų ir lauko deskriptorių kombinacijos. | |
|
era_t_fmt |
Apibrėžia alternatyvų lokalės laiko formatą, kaip
pavaizduota lauko %EX deskriptoriuje. | |
|
era_d_t_fmt |
Apibrėžia alternatyvų lokalės datos ir laiko formatą,
kaip pavaizduota lauko %Ec deskriptoriuje. | |
|
alt_digits |
Apibrėžia alternatyvias eilutes skaitmenims pagal
lauko %o deskriptorių. Atpažįstamos reikšmės
susideda iš grupės kabliataškiais atskirtų eilučių. Pirmoji eilutė
pavaizduoja alternatyvią eilutę skaitmeniui 0, antroji eilutė pavaizduoja
alternatyvą vienetui, ir t.t.. Daugiausia gali būti nurodytos100
alternatyvių eilučių. | |
Laukų
deskriptoriai
LC_TIME lokalę apibrėžiantis failas naudoja laukų deskriptorius
laiko ir datos elementų formatų atvaizdavimui. Iš šių laukų deskriptorių
kombinacijų gaunami kitų laukų deskriptoriai arba laiką ir datą atvaizduojančios
eilutės. Laukų deskriptoriai, naudojami eilučių, susidedančių iš laukų
deskriptorių ir kitų ženklų, formatavime, keičiami jų einamosiomis reikšmėmis.
Visi kiti ženklai kopijuojami be pakeitimų. Toliau išvardintus laukų
deskriptorius naudoja komandos ir paprogramės, kurios užklausia LC_TIME
kategorijos laiko atvaizdavimo formos:
|
%a |
Žymi sutrumpintą savaitės pavadinimą (Pr) apibrėžtą
abday
formuluotėje. |
|
%A |
Žymi pilną savaitės pavadinimą (Pirmadienis)
apibrėžtą day formuluotėje. |
|
%b |
Žymi sutrumpintą mėnesio pavadinimą (Sau) apibrėžtą
abmon
formuluotėje. |
|
%B |
Žymi pilną mėnesio pavadinimą (Sausis) apibrėžtą month
formuluotėje. |
|
%c |
Žymi laiko ir datos formatą apibrėžtą d_t_fmt
formuluotėje. |
|
%C |
Žymi amžių dešimtainiu skaitmeniu (nuo 00 iki
99). |
|
%d |
Žymi mėnesio dieną dešimtainiu skaitmeniu (nuo 01 iki
31). |
|
%D |
Žymi datą formatu %m/%d/%y (05/9/99). |
|
%e |
Žymi mėnesio dieną dešimtainiu skaitmeniu (nuo 01 iki
31). Lauko %e deskriptorius naudoja dviejų
skaitmenų lauką. Jei mėnesio diena nėra dviejų skaitmenų, pirmojo
skaitmens vieta užpildoma tarpo ženklu. |
|
%Ec |
Nurodo lokalei paskirtą alternatyvų datos ir laiko
atvaizdą. |
|
%EC |
Nurodo bazinių metų (periodo) pavadinimą lokalės
alternatyviame atvaizde. |
|
%Ex |
Nurodo lokalės alternatyvų datos atvaizdą. |
|
%EX |
Nurodo lokalės alternatyvų laiko atvaizdą. |
|
%Ey |
NurodoSpecifies the offset from the %EC (year only) field descriptor in the
locale's alternate representation. |
|
%EY |
Nurodo pilną alternatyvų metų atvaizdą. |
|
%Od |
Nurodo mėnesio dieną, naudojant lokalės alternatyvius
skaičių simbolius. |
|
%Oe |
Nurodo mėnesio dieną, naudojant lokalės alternatyvius
skaičių simbolius. |
|
%OH |
Nurodo valandą (24 valandų periode),naudojant lokalės
alternatyvius skaitmenų simbolius. |
|
%OI |
Nurodo valandą (12 valandų periode),naudojant lokalės
alternatyvius skaitmenų simbolius. |
|
%Om |
Nurodo mėnesį, naudojant lokalės alternatyvius
skaitmenų simbolius. |
|
%OM |
Nurodo minutes, naudojant lokalės alternatyvius
skaitmenų simbolius. |
|
%OS |
Nurodo sekundes, naudojant lokalės alternatyvius
skaitmenų simbolius. |
|
%OU |
Nurodo savaitės numerį metuose (pirmoji savaitės
diena yra sekmadienis), naudojant lokalėsalternatyvius skaitmenų
simbolius. |
|
%Ow |
Nurodo savaitės dieną skaičiumi, alternatyviame
lokalės atvaizde (sekmadienis = 0). |
|
%OW |
Nurodo savaitės dieną skaičiumi (pirmoji savaitės
diena - pirmadienis), naudojant lokalės alternatyvius skaitmenų
simbolius. |
|
%Oy |
Nurodo metus (offset from the %C field descriptor) alternatyviame
atvaizde. |
|
%h |
Reiškia mėnesio pavadinimo sutrumpinimą (pavyzdžiui,
sau), apibrėžtą abmon formuluotėje. Šio lauko deskriptorius yra
%b lauko deskriptoriaus sinonimas. |
|
%H |
Atvaizduoja valandas dešimtainiu skaitmeniu (nuo 00
iki 23) pagal 24 valandų laiko indikaciją. |
|
%I |
Atvaizduoja valandas dešimtainiu skaitmeniu (nuo 01
iki 12) pagal 12 valandų laiko indikaciją. |
|
%j |
Atvaizduoja metų dieną dešimtainiu skaitmeniu (nuo
001 iki 366). |
|
%m |
Atvaizduoja metų mėnesį dešimtainiu skaitmeniu (nuo
01 iki 12). |
|
%M |
Atvaizduoja minutes dešimtainiu skaitmeniu (nuo 00
iki 59). |
|
%n |
Pažymi naujos eilutės ženklą . |
|
%N |
Atvaizduoja alternatyvų eros pavadinimą. |
|
%o |
Atvaizduoja alternatyvius eros metus. |
|
%p |
Atvaizduoja a.m. ir p.m. eilutę, apibrėžtą am_pm
formuluotėje. |
|
%r |
Atvaizduoja laiką pagal 12 valandų laiko indikaciją
su a.m./p.m. notacija apibrėžta t_fmt_ampm formuluotėje. |
|
%S |
Atvaizduoja sekundes dešimtainiu skaitmeniu (nuo 00
iki 59). |
|
%t |
Pažymi tabuliacijos ženklą. |
|
%T |
Atvaizduoja 24 valandų laikrodžio laiką %H:%M:%S
formatu (pavyzdžiui, 16:55:15). |
|
%U |
Atvaizduoja savaitės numerį metuose dešimtainiu
skaitmeniu (nuo 00 iki 53). Sekmadienis, arba jo ekvivalentas, apibrėžtas
day
formuluotėje, laikomas pirmąja savaitės diena, apskaičiuojant šio lauko
deskriptoriaus reikšmę. |
|
%w |
Atvaizduoja savaitės dieną dešimtainiu skaitmeniu
(nuo 0 iki 6). Sekmadienis, arba jo ekvivalentas, apibrėžtas day
formuluotėje, laikomas 0 apskaičiuojant šio lauko deskriptoriaus
reikšmę. |
|
%W |
Atvaizduoja savaitės numerį metuose dešimtainiu
skaitmeniu (nuo 00 iki 53). Pirmadienis, arba jo ekvivalentas, apibrėžtas
day
formuluotėje, laikomas pirmąja savaitės diena, apskaičiuojant šio lauko
deskriptoriaus reikšmę. |
|
%x |
Atvaizduoja datos formatą, apibrėžtą d_fmt
formuluotėje. |
|
%X |
Atvaizduoja laiko formatą, apibrėžtą t_fmt
formuluotėje. |
|
%y |
Atvaizduoja amžiaus metus (nuo 00 iki 99). |
|
%Y |
Atvaizduoja metus dešimtainiu skaitmeniu (pavyzdžiui,
1989). |
|
%Z |
Atvaizduoja laiko zonos pavadinimą, jei galime ją
apibrėžti (pavyzdžiui, EST); jei laiko zona neapibrėžta, jokie ženklai
neišvedami. |
|
%% |
Žymi % (procentų) ženklą. |
3.6. LC_MESSAGES kategorija
3.6.1.
Paskirtis
Ši kategorija skirta teigiamų ir neigiamų sistemos atsakymų
aprašymui.
3.6.2.
Aprašymas
Visi LC_MESSAGES kategorijos operandai – eilutės arba
išplėstos įprastinės išraiškos, apgaubtos " " (paprastos kabutėmis). Nuo
raktažodžių, kuriuos jie apibrėžia, šie operandai atskiriami vienu arba keliais
skliausteliais. Dvi gretimos "" (paprastos kabutės) pažymi neapibrėžtą reikšmę.
LC_MESSAGES
kategorijoje naudojami raktiniai žodžiai:
|
copy |
Nurodomas jau esamos lokalės, naudojamos šios
kategorijos aprašymui, pavadinimas. Jei copy
formuluotė įtraukta į failą, joks kitas raktinis žodis negali būti
nurodomas. |
|
Yesexpr |
Nurodoma išplėsta įprastinė išraiška, atvaizduojanti
priimtiną teigiamą atsakymą į klausimą, kai tikimasi teigiamo arba
neigiamo atsakymo. |
|
Noexpr |
Nurodoma išplėsta įprastinė išraiška, atvaizduojanti
priimtiną teigiamą atsakymą į klausimą, kai tikimasi teigiamo arba
neigiamo atsakymo. |
|
Yesstr |
Dvitaškiais perskirta priimtinų teigiamų atsakymų
eilutė. Taikomosioms programoms ši eilutė pasiekiama per nl_langinfo
paprogramę, nl_langinfo (YESSTR). |
|
Nostr |
Dvitaškiais perskirta priimtinų neigiamų atsakymų
eilutė. Taikomosioms programoms ši eilutė pasiekiama per nl_langinfo
paprogramę, nl_langinfo (NOSTR). |
4. Lietuviška POSIX lokalė
4.1. LC_COLLATE kategorijos apibrėžimas
Toliau pateiktas lokalės apibrėžiamojo failo, LC_COLLATE kategorijos apibrėžimas lietuviškai lokalei:
LC_COLLATE
copy en_DK
reorder-after <a>
<A;>
<A>;<OGONEK>;<CAPITAL>
<a;>
<A>;<OGONEK>;<SMALL>
reorder-after <c>
<C<> <C>;<CARON>;<CAPITAL>
<c<>
<C>;<CARON>;<SMALL>
reorder-after <e>
<E;>
<E>;<OGONEK>;<CAPITAL>
<e;>
<E>;<OGONEK>;<SMALL>
<E.> <E>;<DOT
ABOVE>;<CAPITAL>
<e.> <E>;<DOT
ABOVE>;<SMALL>
reorder-after <i>
<I;>
<I>;<OGONEK>;<CAPITAL>
<I;>
<I>;<OGONEK>;<SMALL>
<Y>
<Y>;<NONE>;<CAPITAL>
<y> <Y>;<NONE>;<SMALL>
reorder-after <s>
<S<>
<S>;<CARON>;<CAPITAL>
<s<>
<S>;<CARON>;<SMALL>
reorder-after <u>
<U;>
<U>;<OGONEK>;<CAPITAL>
<u;>
<U>;<OGONEK>;<SMALL>
<U->
<U>;<MACRON>;<CAPITAL>
<u->
<U>;<MACRON>;<SMALL>
reorder-after <z>
<Z<>
<Z>;<CARON>;<CAPITAL>
<z<>
<Z>;<CARON>;<SMALL>
reorder-end
END LC_COLLATE
Pagal tokį apibrėžimą suformuojama štai tokia lietuviškos abėcėlės ženklų rikiavimo tvarka:
Aa Ąą Bb Cc Čč Dd Ee Ęę Ėė Ff Gg Hh Ii Įį Yy Jj Kk Ll Mm Nn Oo Pp Qq Rr Ss Šš Tt Uu Ųų Ūū Vv Ww Xx Zz
Šiame apibrėžime naudojami lietuviškų raidžių atitikmenys nurodomi sutinkamai su en_DK lokale. Toliau 3 lentelėje pateikiami alternatyvūs raidžių atitikmenų pasiūlymai:
3 lentelė. Dabartiniai ir alternatyvūs raidžių žymėjimai LC_COLLATE kategorijoje
|
Raidė |
Sutartinis žymėjimas en_DK lokalėje |
Alternatyvus žymėjimas |
|
<A><OGONEK> |
<A;> |
<A,> |
|
<A><ACUTE> |
<A'> |
<A'> |
|
<A><GRAVE> |
<A!> |
<A`> |
|
<A><TILDE> |
<A?> |
<A~> |
|
<U><MACRON> |
<U-> |
<U_> |
|
<C><CARON> |
<C<> |
<C^> |
Darbo grupės nuomone alternatyvūs žymėjimai geriau atspindi vizualų raidės atvaizdą.
Ateityje vertėtų apibrėžti ir specializuotąją lokalę
lietuvių kalbai, įtraukiant į ženklų aibę ir kirčiuotas raides bei jų
rikiavimą.
4.2. LC_CTYPE kategorija
Toliau pateiktas lokalės apibrėžiamojo failo, LC_CTYPE kategorijos apibrėžimas lietuviškai lokalei:
LC_CTYPE
upper
<A>;<A;>;<B>;<C>;<C<>;<D>;<E>;<E;><E.>;/
<F>;<G>;<H>;<I>;<I;>;<Y>;<J>;<K>;<L>;<M>;/
<N>;<O>;<P>;<Q>;<R>;<S>;<S<>;<T>;<U>;<U;>;/
<U->;<V>;<W>;<X>;<Z>;<Z<>
lower
<a>;<a;>;<b>;<c>;<c<>;<d>;<e>;<e;>;<e.>;/
<f>;<g>;<h>;<i>;<i;>;<y>;<j>;<k>;<l>;<m>;/
<n>;<o>;<p>;<q>;<r>;<s>;<s<>;<t>;<u>;<u;>;/
<u->;<v>;<w>;<x>;<z>;<z<>
digit
<0>;<1>;<2>;<3>;<4>;<5>;<6>;<7>;<8>;<9>
xdigit
<0>;<1>;<2>;<3>;<4>;<5>;<6>;<7>;<8>;<9>;/
<A>;<B>;<C>;<D>;<E>;<F>;/
<a>;<b>;<c>;<d>;<e>;<f>
space
<space>;<form-feed>;<newline>;<carriage
return>;/
<tab>;<vertical-tab>
cntrl
<alert>;<backspace>;<tab>;<newline>;<vertical-tab>;/
<form-feed>;<carriage-return>;<NUL>;<SOH>;<STX>;/
<ETX>;<EOT>;<ENQ>;<ACK>;<SO>;<SI>;<DLE>;<DC1>;<DC2>;/
<DC3>;<DC4>;<NAK>;<SYN>;<ETB>;<CAN>;<EM>;<SUB>;/
<ESC>;<IS4>;<IS3>;<IS2>;<IS1>;<DEL>
punct <exclamation-mark>;<quotation-mark>;<number-sign>;/
<dollar-sign>;<percent-sign>;<ampersand>;<asterisk>;/
<apostrophe>;<left-parenthesis>;<right-parenthesis>; /
<plus-sign>;<comma>;<hyphen>;<period>;<slash>;/
<colon>;<semicolon>;<less-than-sign>;<equals-sign>;/
<greater-than-sign>;<question-mark>;<commercial-at>;/
<left-square-bracket>;<backslash>;<circumflex>;/
<right-square-bracket>;<underline>;<grave-accent>;/
<left-curly-bracket>;<vertical-line>;<tilde>;/
<right-curly-bracket>
blank <space>;<tab>
toupper
(<a>,<A>);(<a;>,<A;>);(<b>,<B>);(<c>,<C>);/
(<c<>,<C<>);(<d>,<D>);(<e>,<E>);(<e;>,<E;>);/
(<e.>,<
E.>);(<f>,<F>);(<g>,<G>);(<h>,<H>);/
(<i>,<I>);(<i;>,<I;>);(<y>,<Y>);(<j>,<J>);/
(<k>,<K>);(<l>,<L>);(<m>,<M>);(<n>,<N>);/
(<o>,<O>);(<p>,<P>);(<q>,<Q>);(<r>,<R>);/
(<s>,<S>);(<s<>,<S<>);(<t>,<T>);(<u>,<U>);/
(<u,>,<U,>);(<u->,<U->);(<v>,<V>);(<w>,<W>);/
(<x>,<X>);(<z>,<Z>);(<z<>,<Z<>)
tolower
(<A>,<a>);(<A,>,<a,>);(<B>,<b>);(<C>,<c>);/
(<C<>,<c<>);(<D>,<d>);(<E>,<e>);(<E;>,<e;>);/
(<E.>,<
e.>);(<F>,<f>);(<G>,<g>);(<H>,<h>);/
(<I>,<i>);(<I;>,<i;>);(<Y>,<y>);(<J>,<j>);/
(<K>,<k>);(<L>,<l>);(<M>,<m>);(<N>,<n>);/
(<O>,<o>);(<P>,<p>);(<Q>,<q>);(<R>,<r>);/
(<S>,<s>);(<S<>,<s<>);(<T>,<t>);(<U>,<u>);/
(<U,>,<u,>);(<U->,<u->);(<V>,<v>);(<W>,<w>);/
(<X>,<x>);(<Z>,<z>);(<Z<>,<z<>)
END LC_TYPE
Iš principo ateityje vertėtų apibrėžti ir specializuotąją
lokalę lietuvių kalbai, įtraukiant į ženklų aibę ir kirčiuotas raides. Reikėtų
taip pat apibrėžti ir jų rikiavimą. Problema apsunkinama tuo, kad ne visos
lietuviškos kirčiuotos raidės turi Unicode kodus.
4.3. LC_NUMERIC kategorija
Toliau pateiktas lokalės apibrėžiamojo failo, LC_NUMERIC kategorijos apibrėžimas lietuviškai lokalei:
LC_NUMERIC
decimal_point "<,>"
thousands_sep "<.>"
grouping 3
END LC_NUMERIC
Skaitmenų grupavimas apibrėžtas, laikantis Lietuvos
standarto LST 1285.
4.4. LC_MONETARY kategorija
Toliau pateiktas lokalės apibrėžiamojo failo, LC_MONETARY kategorijos apibrėžimas lietuviškai lokalei:
LC_MONETARY
int_curr_symbol
"<L><T><L><SP>"
currency_symbol
"<L><t>"
mon_decimal_point "<,>"
mon_thousands_sep
""
mon_grouping
3;3
positive_sign
""
negative_sign
"<->"
int_frac_digits
2
frac_digits
2
p_cs_precedes
0
p_sep_by_space
1
n_cs_precedes
0
n_sep_by_space 1
p_sign_posn
1
n_sign_posn
1
END LC_MONETARY
4.5. LC_TIME kategorija
LC_TIME
abday
"<P><r>";"<A><n>";"<T><r>";"<K><t>";"<P><n>";"<S<><t>";"<S><k>"
day "<P><i><r><m><a><d><i><e><n><i><s>";/
"<A><n><t><r><a><d><i><e><n><i><s>";/
"<T><r><e><c<><i><a><d><i><e><n><i><s>";/
"<K><e><t><v><i><r><t><a><d><i><e><n><i><s>";/
"<P><e><n><k><t><a><d><i><e><n><i><s>";/
"<S<><e><s<><t><a><d><i><e><n><i><s>";/
"<S><e><k><m><a><d><i><e><n><i><s>"
abmon "<S><a><u>";
"<V><a><s>"; "<K><o><v>";/
"<B><a><l>";
"<G><e><g>"; "<B><i><r>";/
"<L><i><e>";
"<R><g><p>"; "<R><g><s>";/
"<S><p><l>";
"<L><a><p>"; "<G><r><d>"
mon
"<s><a><u><s><i><o>";/
"<v><a><s><a><r><i><o>";/
"<k><o><v><o>";/
"<b><a><l><a><n><d><z<><i><o>";/
"<g><e><g><u><z<><ė><s>";/
"<b><i><r><z<><e><l><i><o>";/
"<l><i><e><p><o><s>";/
"<r><u><g><p><j><u-><c<><i><o>";/
"<r><u><g><s><e.><j><o>";/
"<s><p><a><l><i><o>";/
"<l><a><p><k><r><i><c<><i><o>";/
"<g><r><u><o><d><z<><i><o>"
d_t_fmt
d_fmt "
%Y<SP><m><.><SP>%B<SP>%e<d><.>"
t_fmt " %H<:>%M"
am_pm "";""
t_fmt_ampm ""
END LC_TIME
Pavadinimai apibrėžtas, laikantis Lietuvos standarto LST
1285. Tačiau manoma, kad tiek mėnesių ir savaitės dienų pavadinimai, tiek jų
santrumpos turi prasidėti mažąja raide. Mat ši informacija dažniausia vartojama
datos užraše.
4.6. LC_MESSAGES kategorija
LC_MESSAGES
yesexp
"<
<(><T><t><Y><y><)/>><.><*>"
noexp
"<<(><N><n><)/>><.><*>"
END LC_MESSAGES
5. Lietuviškos lokalės koduotė (charmap)
Lietuviškos lokalės koduotei parinkta tarptautinė kodų lentelė ISO-8859-13:2000, įteisinta Lietuvos standartu LST ISO/IEC 8859-13, Informacijos technologija. Informacijos technologija. 8 bitais koduotų ženklų rinkiniai. 13 dalis. Lotynų 7-oji abėcėlė (tapatus ISO/IEC 8859-13:1998). Koduotė pateikta pagal taisykles, suformuluotas tarptautiniame standarte ISO/IEC 9945-2.
POSIX charmap for lt_LT ############################################################################# # This is the ISO/IEC 8859-13 (Latin # 7), covering all languages# listed under Latin # 7 and providing full repertoire for Lithuanian# # This is character definition table for 8859-13 attended to use in lt_LT# locale#############################################################################<code_set_name> ISO-8859-13<escape_char> %<comment_char> /% version: 1.0% source: IANA registry% alias LATIN7
CHARMAP
<NU>
/x00
<U0000> NULL (NUL)
<SH>
/x01
<U0001> START OF HEADING (SOH)
<SX>
/x02
<U0002> START OF TEXT (STX)
<EX>
/x03
<U0003> END OF TEXT (ETX)
<ET>
/x04
<U0004> END OF TRANSMISSION (EOT)
<EQ>
/x05
<U0005> ENQUIRY (ENQ)
<AK>
/x06
<U0006> ACKNOWLEDGE (ACK)
<BL>
/x07
<U0007> BELL (BEL)
<BS>
/x08
<U0008> BACKSPACE (BS)
<HT>
/x09
<U0009> CHARACTER TABULATION (HT)
<LF> /x0A <U000A> LINE
FEED (LF)
<VT>
/x0B
<U000B> LINE TABULATION (VT)
<FF>
/x0C
<U000C> FORM FEED (FF)
<CR>
/x0D
<U000D> CARRIAGE RETURN (CR)
<SO>
/x0E
<U000E> SHIFT OUT (SO)
<SI>
/x0F
<U000F> SHIFT IN (SI)
<DL>
/x10
<U0010> DATALINK ESCAPE (DLE)
<D1>
/x11
<U0011> DEVICE CONTROL ONE (DC1)
<D2>
/x12
<U0012> DEVICE CONTROL TWO (DC2)
<D3>
/x13
<U0013> DEVICE CONTROL THREE (DC3)
<D4>
/x14
<U0014> DEVICE CONTROL FOUR (DC4)
<NK>
/x15
<U0015> NEGATIVE ACKNOWLEDGE (NAK)
<SY>
/x16
<U0016> SYNCHRONOUS IDLE (SYN)
<EB>
/x17
<U0017> END OF TRANSMISSION BLOCK (ETB)
<CN>
/x18
<U0018> CANCEL (CAN)
<EM>
/x19
<U0019> END OF MEDIUM (EM)
<SB>
/x1A
<U001A> SUBSTITUTE (SUB)
<EC>
/x1B
<U001B> ESCAPE (ESC)
<FS>
/x1C
<U001C> FILE SEPARATOR (IS4)
<GS>
/x1D
<U001D> GROUP SEPARATOR (IS3)
<RS>
/x1E
<U001E> RECORD SEPARATOR (IS2)
<US>
/x1F
<U001F> UNIT SEPARATOR (IS1)
<SP>
/x20
<U0020> SPACE
<!>
/x21
<U0021> EXCLAMATION MARK
<">
/x22
<U0022> QUOTATION MARK
<Nb>
/x23
<U0023> NUMBER SIGN
<DO>
/x24
<U0024> DOLLAR SIGN
<%>
/x25
<U0025> PERCENT SIGN
<&>
/x26
<U0026> AMPERSAND
<'>
/x27
<U0027> APOSTROPHE
<(>
/x28
<U0028> LEFT PARENTHESIS
<)>
/x29
<U0029> RIGHT PARENTHESIS
<*>
/x2A
<U002A> ASTERISK
<+>
/x2B
<U002B> PLUS SIGN
<,>
/x2C
<U002C> COMMA
<->
/x2D
<U002D> HYPHEN-MINUS
<.>
/x2E
<U002E> FULL STOP
<//>
/x2F
<U002F> SOLIDUS
<0>
/x30
<U0030> DIGIT ZERO
<1>
/x31
<U0031> DIGIT ONE
<2>
/x32
<U0032> DIGIT TWO
<3>
/x33
<U0033> DIGIT THREE
<4>
/x34
<U0034> DIGIT FOUR
<5>
/x35
<U0035> DIGIT FIVE
<6>
/x36
<U0036> DIGIT SIX
<7>
/x37
<U0037> DIGIT SEVEN
<8>
/x38
<U0038> DIGIT EIGHT
<9> /x39 <U0039> DIGIT
NINE
<:>
/x3A
<U003A> COLON
<;>
/x3B
<U003B> SEMICOLON
<<>
/x3C
<U003C> LESS-THAN SIGN
<=>
/x3D
<U003D> EQUALS SIGN
</>>
/x3E
<U003E> GREATER-THAN SIGN
<?>
/x3F
<U003F> QUESTION MARK
<At>
/x40
<U0040> COMMERCIAL AT
<A>
/x41
<U0041> LATIN CAPITAL LETTER A
<B>
/x42
<U0042> LATIN CAPITAL LETTER B
<C>
/x43
<U0043> LATIN CAPITAL LETTER C
<D>
/x44
<U0044> LATIN CAPITAL LETTER D
<E>
/x45
<U0045> LATIN CAPITAL LETTER E
<F>
/x46
<U0046> LATIN CAPITAL LETTER F
<G>
/x47
<U0047> LATIN CAPITAL LETTER G
<H>
/x48
<U0048> LATIN CAPITAL LETTER H
<I>
/x49
<U0049> LATIN CAPITAL LETTER I
<J> /x4A <U004A> LATIN
CAPITAL LETTER J
<K>
/x4B
<U004B> LATIN CAPITAL LETTER K
<L>
/x4C
<U004C> LATIN CAPITAL LETTER L
<M>
/x4D
<U004D> LATIN CAPITAL LETTER M
<N>
/x4E
<U004E> LATIN CAPITAL LETTER N
<O>
/x4F <U004F> LATIN CAPITAL LETTER O
<P>
/x50
<U0050> LATIN CAPITAL LETTER P
<Q>
/x51
<U0051> LATIN CAPITAL LETTER Q
<R>
/x52
<U0052> LATIN CAPITAL LETTER R
<S>
/x53
<U0053> LATIN CAPITAL LETTER S
<T>
/x54 <U0054> LATIN CAPITAL LETTER T
<U>
/x55
<U0055> LATIN CAPITAL LETTER U
<V>
/x56
<U0056> LATIN CAPITAL LETTER V
<W>
/x57
<U0057> LATIN CAPITAL LETTER W
<X>
/x58
<U0058> LATIN CAPITAL LETTER X
<Y>
/x59
<U0059> LATIN CAPITAL LETTER Y
<Z>
/x5A
<U005A> LATIN CAPITAL LETTER Z
<<(>
/x5B
<U005B> LEFT SQUARE BRACKET
<////>
/x5C
<U005C> REVERSE SOLIDUS
<)/>>
/x5D
<U005D> RIGHT SQUARE BRACKET
<'/>>
/x5E
<U005E> CIRCUMFLEX ACCENT
<_>
/x5F
<U005F> LOW LINE
<'!>
/x60
<U0060> GRAVE ACCENT
<a>
/x61
<U0061> LATIN SMALL LETTER A
<b>
/x62
<U0062> LATIN SMALL LETTER B
<c>
/x63
<U0063> LATIN SMALL LETTER C
<d>
/x64
<U0064> LATIN SMALL LETTER D
<e>
/x65
<U0065> LATIN SMALL LETTER E
<f>
/x66
<U0066> LATIN SMALL LETTER F
<g>
/x67
<U0067> LATIN SMALL LETTER G
<h>
/x68
<U0068> LATIN SMALL LETTER H
<i>
/x69
<U0069> LATIN SMALL LETTER I
<j>
/x6A
<U006A> LATIN SMALL LETTER J
<k>
/x6B
<U006B> LATIN SMALL LETTER K
<l>
/x6C
<U006C> LATIN SMALL LETTER L
<m>
/x6D
<U006D> LATIN SMALL LETTER M
<n>
/x6E
<U006E> LATIN SMALL LETTER N
<o> /x6F <U006F> LATIN
SMALL LETTER O
<p>
/x70
<U0070> LATIN SMALL LETTER P
<q>
/x71
<U0071> LATIN SMALL LETTER Q
<r>
/x72
<U0072> LATIN SMALL LETTER R
<s>
/x73
<U0073> LATIN SMALL LETTER S
<t>
/x74
<U0074> LATIN SMALL LETTER T
<u>
/x75
<U0075> LATIN SMALL LETTER U
<v>
/x76
<U0076> LATIN SMALL LETTER V
<w>
/x77
<U0077> LATIN SMALL LETTER W
<x>
/x78
<U0078> LATIN SMALL LETTER X
<y>
/x79
<U0079> LATIN SMALL LETTER Y
<z>
/x7A
<U007A> LATIN SMALL LETTER Z
<(!>
/x7B
<U007B> LEFT CURLY BRACKET
<!!>
/x7C
<U007C> VERTICAL LINE
<!)>
/x7D
<U007D> RIGHT CURLY BRACKET
<'?>
/x7E
<U007E> TILDE
<DT>
/x7F
<U007F> DELETE (DEL)
<PA> /x80 <U0080> PADDING CHARACTER (PAD)<HO> /x81 <U0081> HIGH OCTET PRESET (HOP)<BH> /x82 <U0082> BREAK PERMITTED HERE (BPH)<NH> /x83 <U0083> NO BREAK HERE (NBH)<IN> /x84 <U0084> INDEX (IND)<NL> /x85 <U0085> NEXT LINE (NEL)<SA> /x86 <U0086> START OF SELECTED AREA (SSA)<ES> /x87 <U0087> END OF SELECTED AREA (ESA)<HS> /x88 <U0088> CHARACTER TABULATION SET (HTS)<HJ> /x89 <U0089> CHARACTER TABULATION WITH JUSTIFICATION (HTJ)<VS> /x8A <U008A> LINE TABULATION SET (VTS)<PD> /x8B <U008B> PARTIAL LINE FORWARD (PLD)<PU> /x8C <U008C> PARTIAL LINE BACKWARD (PLU)<RI> /x8D <U008D> REVERSE LINE FEED (RI)<S2> /x8E <U008E> SINGLE-SHIFT TWO (SS2)<S3> /x8F <U008F> SINGLE-SHIFT THREE (SS3)<DC> /x90 <U0090> DEVICE CONTROL STRING (DCS)<P1> /x91 <U0091> PRIVATE USE ONE (PU1)<P2> /x92 <U0092> PRIVATE USE TWO (PU2)<TS> /x93 <U0093> SET TRANSMIT STATE (STS)<CC> /x94 <U0094> CANCEL CHARACTER (CCH)<MW> /x95 <U0095> MESSAGE WAITING (MW)<SG> /x96 <U0096> START OF GUARDED AREA (SPA)<EG> /x97 <U0097> END OF GUARDED AREA (EPA)<SS> /x98 <U0098> START OF STRING (SOS)<GC> /x99 <U0099> SINGLE GRAPHIC CHARACTER INTRODUCER (SGCI)<SC> /x9A <U009A> SINGLE CHARACTER INTRODUCER (SCI)<CI> /x9B <U009B> CONTROL SEQUENCE INTRODUCER (CSI)<ST> /x9C <U009C> STRING TERMINATOR (ST)<OC> /x9D <U009D> OPERATING SYSTEM COMMAND (OSC)<PM> /x9E <U009E> PRIVACY MESSAGE (PM)<AC> /x9F <U009F> APPLICATION PROGRAM COMMAND (APC)
<NS>
/xA0
<U00A0> NO-BREAK SPACE
<"9>
/xA1
<U201D> RIGHT DOUBLE QUOTATION MARK
<Ct>
/xA2
<U00A2> CENT SIGN
<Pd>
/xA3
<U00A3> POUND SIGN
<Cu>
/xA4
<U00A4> CURRENCY SIGN
<:9>
/xA5
<U201E> DOUBLE LOW-9 QUOTATION MARK
<BB> /xA6 <U00A6>
BROKEN BAR
<SE>
/xA7
<U00A7> SECTION SIGN
<O//>
/xA8
<U00D8> LATIN CAPITAL LETTER O WITH STROKE
<Co>
/xA9
<U00A9> COPYRIGHT SIGN
<R,>
/xAA
<U0156> LATIN CAPITAL LETTER R WITH CEDILLA
<<<>
/xAB
<U00AB> LEFT-POINTING DOUBLE ANGLE QUOTATION MARK
<NO>
/xAC
<U00AC> NOT SIGN
<-->
/xAD
<U00AD> SOFT HYPHEN
<Rg>
/xAE
<U00AE> REGISTERED SIGN
<AE>
/xAF
<U00C6> LATIN CAPITAL LETTER AE
<DG>
/xB0
<U00B0> DEGREE SIGN
<+->
/xB1
<U00B1> PLUS-MINUS SIGN
<2S>
/xB2
<U00B2> SUPERSCRIPT TWO
<3S>
/xB3
<U00B3> SUPERSCRIPT THREE
<"6>
/xB4
<U201C> LEFT DOUBLE QUOTATION MARK
<My>
/xB5
<U00B5> MICRO SIGN
<PI>
/xB6
<U00B6> PILCROW SIGN
<.M>
/xB7
<U00B7> MIDDLE DOT
<o//>
/xB8
<U00F8> LATIN SMALL LETTER O WITH STROKE
<1S>
/xB9
<U00B9> SUPERSCRIPT ONE
<r,>
/xBA
<U0157> LATIN SMALL LETTER R WITH CEDILLA
</>/>>
/xBB
<U00BB> RIGHT-POINTING DOUBLE ANGLE QUOTATION MARK
<14>
/xBC
<U00BC> VULGAR FRACTION ONE QUARTER
<12>
/xBD
<U00BD> VULGAR FRACTION ONE HALF
<34>
/xBE
<U00BE> VULGAR FRACTION THREE QUARTERS
<ae>
/xBF
<U00E6> LATIN SMALL LETTER AE
<A;>
/xC0
<U0104> LATIN CAPITAL LETTER A WITH OGONEK
<I;>
/xC1
<U012E> LATIN CAPITAL LETTER I WITH OGONEK
<A->
/xC2
<U0100> LATIN CAPITAL LETTER A WITH MACRON
<C'>
/xC3
<U0106> LATIN CAPITAL LETTER C WITH ACUTE
<A:>
/xC4
<U00C4> LATIN CAPITAL LETTER A WITH DIAERESIS
<AA>
/xC5
<U00C5> LATIN CAPITAL LETTER A WITH RING ABOVE
<E;>
/xC6
<U0118> LATIN CAPITAL LETTER E WITH OGONEK
<E->
/xC7
<U0112> LATIN CAPITAL LETTER E WITH MACRON
<C<>
/xC8
<U010C> LATIN CAPITAL LETTER C WITH CARON
<E'>
/xC9
<U00C9> LATIN CAPITAL LETTER E WITH ACUTE
<Z'>
/xCA
<U0179> LATIN CAPITAL LETTER Z WITH ACUTE
<E.>
/xCB
<U0116> LATIN CAPITAL LETTER E WITH DOT ABOVE
<G,>
/xCC
<U0122> LATIN CAPITAL LETTER G WITH CEDILLA
<K,>
/xCD
<U0136> LATIN CAPITAL LETTER K WITH CEDILLA
<I->
/xCE
<U012A> LATIN CAPITAL LETTER I WITH MACRON
<L,>
/xCF
<U013B> LATIN CAPITAL LETTER L WITH CEDILLA
<S<>
/xD0
<U0160> LATIN CAPITAL LETTER S WITH CARON
<N'>
/xD1
<U0143> LATIN CAPITAL LETTER N WITH ACUTE
<N,>
/xD2
<U0145> LATIN CAPITAL LETTER N WITH CEDILLA
<O'>
/xD3
<U00D3> LATIN CAPITAL LETTER O WITH ACUTE
<O->
/xD4
<U014C> LATIN CAPITAL LETTER O WITH MACRON
<O?>
/xD5
<U00D5> LATIN CAPITAL LETTER O WITH TILDE
<O:>
/xD6
<U00D6> LATIN CAPITAL LETTER O WITH DIAERESIS
<*X>
/xD7
<U00D7> MULTIPLICATION SIGN
<U;>
/xD8
<U0172> LATIN CAPITAL LETTER U WITH OGONEK
<L//>
/xD9
<U0141> LATIN CAPITAL LETTER L WITH STROKE
<S'>
/xDA
<U015A> LATIN CAPITAL LETTER S WITH ACUTE
<U->
/xDB
<U016A> LATIN CAPITAL LETTER U WITH MACRON
<U:>
/xDC
<U00DC> LATIN CAPITAL LETTER U WITH DIAERESIS
<Z.>
/xDD
<U017B> LATIN CAPITAL LETTER Z WITH DOT ABOVE
<Z<>
/xDE
<U017D> LATIN CAPITAL LETTER Z WITH CARON
<ss>
/xDF
<U00DF> LATIN SMALL LETTER SHARP S (German)
<a;>
/xE0
<U0105> LATIN SMALL LETTER A WITH OGONEK
<i;>
/xE1
<U012F> LATIN SMALL LETTER I WITH OGONEK
<a->
/xE2
<U0101> LATIN SMALL LETTER A WITH MACRON
<c'>
/xE3
<U0107> LATIN SMALL LETTER C WITH ACUTE
<a:>
/xE4
<U00E4> LATIN SMALL LETTER A WITH DIAERESIS
<aa>
/xE5
<U00E5> LATIN SMALL LETTER A WITH RING ABOVE
<e;>
/xE6
<U0119> LATIN SMALL LETTER E WITH OGONEK
<e->
/xE7
<U0113> LATIN SMALL LETTER E WITH MACRON
<c<>
/xE8
<U010D> LATIN SMALL LETTER C WITH CARON
<e'>
/xE9
<U00E9> LATIN SMALL LETTER E WITH ACUTE
<z'>
/xEA
<U017A> LATIN SMALL LETTER Z WITH ACUTE
<e.>
/xEB
<U0117> LATIN SMALL LETTER E WITH DOT ABOVE
<g,>
/xEC
<U0123> LATIN SMALL LETTER G WITH CEDILLA
<k,>
/xED
<U0137> LATIN SMALL LETTER K WITH CEDILLA
<i->
/xEE
<U012B> LATIN SMALL LETTER I WITH MACRON
<l,>
/xEF
<U013C> LATIN SMALL LETTER L WITH CEDILLA
<s<>
/xF0
<U0161> LATIN SMALL LETTER S WITH CARON
<n'>
/xF1
<U0144> LATIN SMALL LETTER N WITH ACUTE
<n,>
/xF2
<U0146> LATIN SMALL LETTER N WITH CEDILLA
<o'>
/xF3
<U00F3> LATIN SMALL LETTER O WITH ACUTE
<o->
/xF4
<U014D> LATIN SMALL LETTER O WITH MACRON
<o?>
/xF5
<U00F5> LATIN SMALL LETTER O WITH TILDE
<o:>
/xF6
<U00F6> LATIN SMALL LETTER O WITH DIAERESIS
<-:>
/xF7
<U00F7> DIVISION SIGN
<u;>
/xF8
<U0173> LATIN SMALL LETTER U WITH OGONEK
<l//>
/xF9
<U0142> LATIN SMALL LETTER L WITH STROKE
<s'>
/xFA
<U015B> LATIN SMALL LETTER S WITH ACUTE
<u->
/xFB
<U016B> LATIN SMALL LETTER U WITH MACRON
<u:>
/xFC
<U00FC> LATIN SMALL LETTER U WITH DIAERESIS
<z.>
/xFD
<U017C> LATIN SMALL LETTER Z WITH DOT ABOVE
<z<>
/xFE
<U017E> LATIN SMALL LETTER Z WITH CARON
<.9>
/xFF
<U201A> SINGLE LOW-9 QUOTATION MARK
END CHARMAP
1. Webster’s Revised Unabridged Dictionary (1913).
2. LST ISO/IEC 15897:2001 Informacijos
technologija. Kultūros elementų registravimo procedūros (tapatus ISO/IEC
15897:1999 Information technology – Procedures for registration of
cultural elements)
3. LST ISO/IEC 8859-13:2000 Informacijos
technologija. 8 bitais koduotų ženklų rinkiniai. 13 dalis. Lotynų 7-oji abėcėlė
(tapatus ISO/IEC 8859-13:1998 Information technology – 8-bit single-byte coded graphic
character sets – Part:13: Latin alphabet No. 7).
4. LST 1564. Informacijos technologija. Ženklų kodavimas 8 bitais.
Lietuviškų kirčiuotų raidžių rinkinys
5. LST 1590-1 Informacijos technologija. Ženklų kodavimas 8 bitais.
Grafinių ženklų rinkinys DOS terpei.
6. LST 1590-2 Informacijos technologija. Ženklų kodavimas 8 bitais.
Lietuviškų kirčiuotų raidžių ir fonetinių ženklų rinkinys DOS terpei.
7. LST 1590-3 Informacijos technologija. Ženklų kodavimas 8 bitais.
Grafinių ženklų rinkinys Windows terpei.
8. LST 1590-4. Informacijos technologija. Ženklų kodavimas 8 bitais.
Lietuviškų kirčiuotų raidžių ir fonetinių ženklų rinkinys „Windows“
terpei.
9. LST ISO/IEC 10646-1 Informacijos
technologija. Universalus keliais baitais koduotų ženklų rinkinys. 1 dalis.
Sandara ir pagrindinė daugiakalbė lentelė (tapatus ISO/IEC 10646-1:2000 Information technology
– Universal Multiple-Octet Coded Character Set (UCS) – Part1: Architecture and
Basic Multilingual Plane (BMP))
10. LST 1582:2000. Informacijos
technologija. Lietuviška kompiuterio klaviatūra. Ženklų išdėstymas.
11. LST 1285:1993 Informacijos
technologija. Lietuvių kalbos ypatybės.
12. LST ISO/IEC 2382 Informacijos technologija. Terminai ir apibrėžimai (25
dalys).
13. LST ISO 8601:1997 Duomenų elementai ir
pasikeitimo informacija formatai. Datų ir laiko žymėjimas.
14. ISO/IEC 9945-2:1993 Information technology
– Portable Operating System Interface (POSIX) Part 2: Shell and Utilities.
15. ISO/IEC DTR 14652, Information technology
– Specification method for cultural conventions.
16. ISO 639:1988 Code for the representation of names of languages.
17. ISO/IEC 646:1991 Information technology
– ISO 7-bit coded character set for information interchange.
18. ISO 3166 (all parts) Codes for the
representation of names of countries and their subdivisions.
19. ISO 4217:1995 Codes for the representation of currencies and
funds.
20. ISO 8601:1988 Data elements and
interchange formats – Information interchange – Representation of dates and
times.
21. ISO/IEC 8824:1990 Information technology
– Open Systems Interconnection – Specification of Abstract Syntax Notation One
(ASN.1).
22. ISO/IEC 8825:1990 Information technology
– Open Systems Interconnection – Specification of Basic Encoding Rules for
Abstract Syntax Notation One (ASN.1).
1 priedas. POSIX lokalė lietuvių kalbai
LC_CTYPE
upper
<A>;<A;>;<B>;<C>;<C<>;<D>;<E>;<E;><E.>;/
<F>;<G>;<H>;<I>;<I;>;<Y>;<J>;<K>;<L>;<M>;/
<N>;<O>;<P>;<Q>;<R>;<S>;<S<>;<T>;<U>;<U;>;/
<U->;<V>;<W>;<X>;<Z>;<Z<>
lower
<a>;<a;>;<b>;<c>;<c<>;<d>;<e>;<e;>;<e.>;/
<f>;<g>;<h>;<i>;<i;>;<y>;<j>;<k>;<l>;<m>;/
<n>;<o>;<p>;<q>;<r>;<s>;<s<>;<t>;<u>;<u;>;/
<u->;<v>;<w>;<x>;<z>;<z<>
digit
<0>;<1>;<2>;<3>;<4>;<5>;<6>;<7>;<8>;<9>
xdigit
<0>;<1>;<2>;<3>;<4>;<5>;<6>;<7>;<8>;<9>;/
<A>;<B>;<C>;<D>;<E>;<F>;/
<a>;<b>;<c>;<d>;<e>;<f>
space
<space>;<form-feed>;<newline>;<carriage
return>;/
<tab>;<vertical-tab>
cntrl
<alert>;<backspace>;<tab>;<newline>;<vertical-tab>;/
<form-feed>;<carriage-return>;<NUL>;<SOH>;<STX>;/
<ETX>;<EOT>;<ENQ>;<ACK>;<SO>;<SI>;<DLE>;<DC1>;<DC2>;/
<DC3>;<DC4>;<NAK>;<SYN>;<ETB>;<CAN>;<EM>;<SUB>;/
<ESC>;<IS4>;<IS3>;<IS2>;<IS1>;<DEL>
punct <exclamation-mark>;<quotation-mark>;<number-sign>;/
<dollar-sign>;<percent-sign>;<ampersand>;<asterisk>;/
<apostrophe>;<left-parenthesis>;<right-parenthesis>; /
<plus-sign>;<comma>;<hyphen>;<period>;<slash>;/
<colon>;<semicolon>;<less-than-sign>;<equals-sign>;/
<greater-than-sign>;<question-mark>;<commercial-at>;/
<left-square-bracket>;<backslash>;<circumflex>;/
<right-square-bracket>;<underline>;<grave-accent>;/
<left-curly-bracket>;<vertical-line>;<tilde>;/
<right-curly-bracket>
blank <space>;<tab>
toupper
(<a>,<A>);(<a;>,<A;>);(<b>,<B>);(<c>,<C>);/
(<c<>,<C<>);(<d>,<D>);(<e>,<E>);(<e;>,<E;>);/
(<e.>,<
E.>);(<f>,<F>);(<g>,<G>);(<h>,<H>);/
(<i>,<I>);(<i;>,<I;>);(<y>,<Y>);(<j>,<J>);/
(<k>,<K>);(<l>,<L>);(<m>,<M>);(<n>,<N>);/
(<o>,<O>);(<p>,<P>);(<q>,<Q>);(<r>,<R>);/
(<s>,<S>);(<s<>,<S<>);(<t>,<T>);(<u>,<U>);/
(<u,>,<U,>);(<u->,<U->);(<v>,<V>);(<w>,<W>);/
(<x>,<X>);(<z>,<Z>);(<z<>,<Z<>)
tolower
(<A>,<a>);(<A,>,<a,>);(<B>,<b>);(<C>,<c>);/
(<C<>,<c<>);(<D>,<d>);(<E>,<e>);(<E;>,<e;>);/
(<E.>,<
e.>);(<F>,<f>);(<G>,<g>);(<H>,<h>);/
(<I>,<i>);(<I;>,<i;>);(<Y>,<y>);(<J>,<j>);/
(<K>,<k>);(<L>,<l>);(<M>,<m>);(<N>,<n>);/
(<O>,<o>);(<P>,<p>);(<Q>,<q>);(<R>,<r>);/
(<S>,<s>);(<S<>,<s<>);(<T>,<t>);(<U>,<u>);/
(<U,>,<u,>);(<U->,<u->);(<V>,<v>);(<W>,<w>);/
(<X>,<x>);(<Z>,<z>);(<Z<>,<z<>)
END LC_TYPE
LC_COLLATE
copy en_DK
reorder-after <a>
<A;> <A>;<OGONEK>;<CAPITAL>
<a;> <A>;<OGONEK>;<SMALL>
reorder-after <c>
<C<>
<C>;<CARON>;<CAPITAL>
<c<> <C>;<CARON>;<SMALL>
reorder-after <e>
<E;> <E>;<OGONEK>;<CAPITAL>
<e;> <E>;<OGONEK>;<SMALL>
<E.> <E>;<DOT
ABOVE>;<CAPITAL>
<e.> <E>;<DOT ABOVE>;<SMALL>
reorder-after <i>
<I;>
<I>;<OGONEK>;<CAPITAL>
<I;>
<I>;<OGONEK>;<SMALL>
<Y> <Y>;<NONE>;<CAPITAL>
<y>
<Y>;<NONE>;<SMALL>
reorder-after <s>
<S<> <S>;<CARON>;<CAPITAL>
<s<> <S>;<CARON>;<SMALL>
reorder-after <u>
<U;> <U>;<OGONEK>;<CAPITAL>
<u;> <U>;<OGONEK>;<SMALL>
<U-> <U>;<MACRON>;<CAPITAL>
<u-> <U>;<MACRON>;<SMALL>
reorder-after <z>
<Z<> <Z>;<CARON>;<CAPITAL>
<z<> <Z>;<CARON>;<SMALL>
reorder-end
END LC_COLLATE
LC_MONETARY
int_curr_symbol
"<L><T><L><SP>"
currency_symbol
"<L><t>"
mon_decimal_point
"<,>"
mon_thousands_sep ""
mon_grouping
3;3
positive_sign
""
negative_sign
"<->"
int_frac_digits
2
frac_digits
2
p_cs_precedes
0
p_sep_by_space 1
n_cs_precedes
0
n_sep_by_space 1
p_sign_posn
1
n_sign_posn
1
END LC_MONETARY
LC_NUMERIC
decimal_point "<,>"
thousands_sep "<.>"
grouping 3
END LC_NUMERIC
LC_TIME
abday
"<P><r>";"<A><n>";"<T><r>";"<K><t>";"<P><n>";"<S<><t>";"<S><k>"
day
"<P><i><r><m><a><d><i><e><n><i><s>";/
"<A><n><t><r><a><d><i><e><n><i><s>";/
"<T><r><e><c<><i><a><d><i><e><n><i><s>";/
"<K><e><t><v><i><r><t><a><d><i><e><n><i><s>";/
"<P><e><n><k><t><a><d><i><e><n><i><s>";/
"<S<><e><s<><t><a><d><i><e><n><i><s>";/
"<S><e><k><m><a><d><i><e><n><i><s>"
abmon "<S><a><u>";
"<V><a><s>"; "<K><o><v>";/
"<B><a><l>";
"<G><e><g>"; "<B><i><r>";/
"<L><i><e>";
"<R><g><p>"; "<R><g><s>";/
"<S><p><l>";
"<L><a><p>"; "<G><r><d>"
mon
"<s><a><u><s><i><o>";/
"<v><a><s><a><r><i><o>";/
"<k><o><v><o>";/
"<b><a><l><a><n><d><z<><i><o>";/
"<g><e><g><u><z<><ė><s>";/
"<b><i><r><z<><e><l><i><o>";/
"<l><i><e><p><o><s>";/
"<r><u><g><p><j><u-><c<><i><o>";/
"<r><u><g><s><e.><j><o>";/
"<s><p><a><l><i><o>";/
"<l><a><p><k><r><i><c<><i><o>";/
"<g><r><u><o><d><z<><i><o>"
d_t_fmt
d_fmt "
%Y<SP><m><.><SP>%B<SP>%e<d><.>"
t_fmt " %H<:>%M"
am_pm "";""
t_fmt_ampm ""
END LC_TIME
LC_MESSAGES
yesexp
"<
<(><T><t><Y><y><)/>><.><*>"
noexp
"<<(><N><n><)/>><.><*>"
END LC_MESSAGES
2 priedas. ISO 5589-13 lentelė
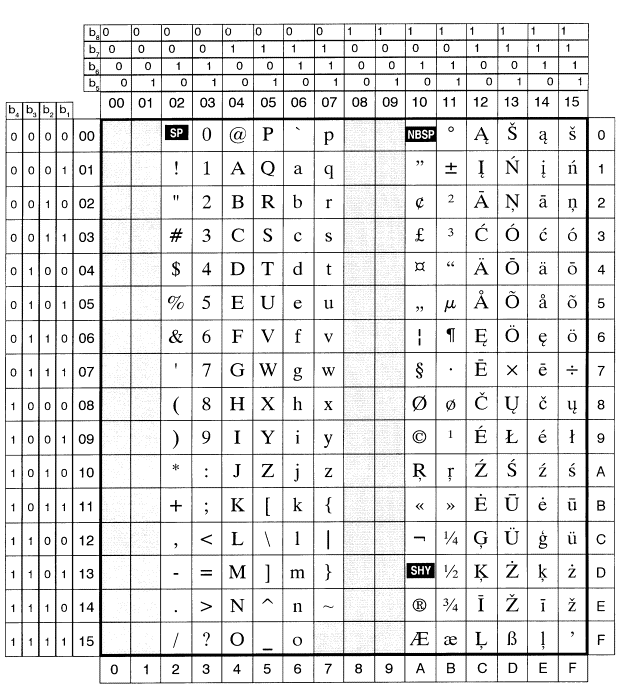
Į pradžią
3 priedas. LST 1564 lentelė

Į pradžią
4 priedas. LST 1590-1 lentelė (775)

Į pradžią
5 priedas. LST 1590-2 lentelė
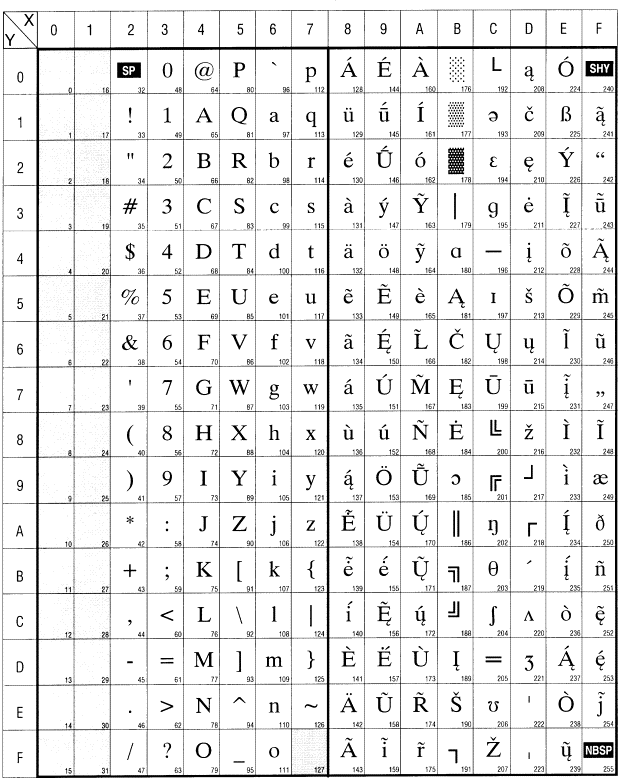
Į pradžią
6 priedas. LST 1590-3 lentelė (1257)

Į pradžią
7 priedas. LST 1590-4 lentelė
