4. MOKSLINIAI IR TAIKOMIEJI BALSO TECHNOLOGIJŲ DARBAI LIETUVOJE
Moksliniai tiriamieji darbai balso technologijų srityje daugelį metų Lietuvoje vykdomi Kauno technologijos universitete, Vilniaus universitete, Matematikos ir informatikos institute. Vytauto Didžiojo universitete taip pat plėtojami balso analizės darbai. Lietuvos teismo ekspertizės centre jau apie 10 metų veikia fonoskopinių ekspertizių skyrius, kuriame balso technologijų pasiekimai taikomi teisėsaugos reikalams, bei vykdomi moksliniai tyrimai. Svarbiu žingsniu laikome valstybinę Lietuvių kalbos informacinėje visuomenėje 2000-2006 metų programą, kurioje nemažas dėmesys skiriamas lituanistiniams balso technologijų aspektams. Šiame skyriuje pristatoma šių institucijų veikla kalbos signalų apdorojimo srityje. Tikimasi, kad šis puslapio skyrius bus nuolat papildomas.
4.1 Kauno Technologijos
Universitetas
4.1.3. Požymių analizė suvokimo eksperimentuose
4.1.4. Projekcinis atpažinimas
4.1.5. Pilnai fonetinis atpažinimas
4.1.7. Diskretinis HMM modelis
4.1.8. Pašalinių garsų atmetimas ( out of vocabulary ).
4.1.9. Kalbos signalų aptikimas
4.1.10. Reguliarizuota diskriminantinė analizė
4.2.1. Kalbos signalų apdorojimo priemonės
4.2.2. Automatinis žodžių kirčiavimas
4.2.3. Automatinis teksto transkribavimas
4.2.5. Sintezuotos kalbos kokybės įvertinimas
4.2.6. Automatinis teksto skiemenavimas
4.3. Lietuvos teismo ekspertizės
centro Fonoskopinių ekspertizių skyrius
4.3.1 LTEC FES veikla ir esama būklė
4.3.2 Problemos ir tolesnio vystymo perspektyvos LTEC FES
Moksliniai tiriamieji darbai balso technologijų srityje daugelį metų Lietuvoje vykdomi Kauno technologijos universitete ir Vilniaus universitete. Lietuvos teismo ekspertizės centre jau apie 10 metų veikia fonoskopinių ekspertizių skyrius, kuriame balso technologijų pasiekimai taikomi teisėsaugos reikalams, bei vykdomi moksliniai tyrimai. Šiame skyriuje pristatoma šių institucijų veikla kalbos signalų apdorojimo srityje.
4.1 Kauno Technologijos Universitetas
KTU Kalbos signalų tyrimo grupė per keletą dešimtmečių vykdė darbus įvairiose balso technologijų srityse. Tolesniuose skyreliuose aprašoma šios grupė veikla iliustruoja pasiekimus įvairiose kalbos signalų apdorojimo srityse.
4.1.1. Atvirkštinė filtracija
Problema ir jos sprendimas. Prieš 1980 metus, pasinaudojant tam laikui naujomis skaitmeninių atminčių technologinėmis priemonėmis, buvo sukonstruota nestacionarių (signalų) analizės sistema. Ji buvo pritaikyta atvirkštinės filtracijos uždavinių, t.y. balso stygų virpesių atstatymui, kai yra žinomas mikrofonu užfiksuotas įrašas. Siekta suformuoti dėsningumus, kuriuos būtų galima taikyti kalbos sintezei. Iš esmės tam reikėjo labai aukštos kokybės kondensatorinio mikrofono, žemų dažnių ( iki 0.5 Hz ) kompensavimo metodikos ir tinkamų kalbos trakto įtakos filtravimo priemonių panaudojimo.
Rezultatai. 1 pav. parodysime porą pastebėtų faktų [1]. Pirma, eksperimentiškai buvo fiksuojami teoriškai pagrįsti balso stygų virpesiai; antra skiemens ribose yra matoma oro srauto “nuolatinė” dedamoji, o fono ribose yra aiškiai stebimas balso stygų judėjimo periodas, įskaitant stygų uždarymo fazę.
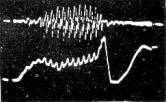
1 pav. Atvirkštinės filtracijos pavyzdžiai skiemens ir garso ( fono) atvejais.
Aukščiau – signalo atkarpa, žemiau – fono atkarpa.
Darbo reikšmė. Šios problemos dabar atgimsta medicininių LOR taikymų šviesoje ( diagnostika, stebėjimas operacijos metu, pooperacinė reabilitacija ).
1) S. Noreika, A. Rudžionis. Žadinimo šaltinio analizė naudojant atvirkštinę filtraciją. // ARSO medžiaga. Jerevanas, 1980, p. 139 - 142 ( rusų k. ).
4.1.2. Žodyno turinio įtaka
Problema ir jos sprendimas. Buvo atlikta serija eksperimentų [1], tam kad palyginti žodyno struktūros įtaką atpažinimo tikslumui. Buvo lyginami du rusiškų žodžių rinkiniai: skaitmenų nuo 0 iki 10 vardai ( nul,odin,dva… ) ir skaitmenų nuo 11 iki 20 vardai ( odinatcatj,dvenatcatj… ). Yra žinoma bendra taisyklė, kad ilgesnius žodžius automatas atpažįsta geriau.
Rezultatai. 1 pav. pagal [1] pateiktos minėtų žodžių rinkinių atpažinimo klaidos. Čia matome, kad, nors panaudotas gerokai platesnis apmokymas ir informatyvesni požymiai, vis tiek pirmo rinkinio atpažinimo tikslumas yra žymiai geresnis. Tai paaiškinama žodyno žodžių struktūros skirtumais – antrame rinkinyje yra mažai besiskiriantis žodžiai, o jų skirtingos dalys yra nekirtinėje pozicijoje.
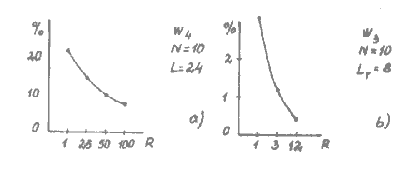
1 pav. Dviejų žodžių rinkinių atpažinimo klaidos ( kairėje pirma dešimtis rusiškų
skaitmenų pavadinimų, antroje – antra dešimtis), kur R –apmokymo imtis, L –požymių skaičius.
Darbo reikšmė. Buvo papildytos žinios apie žodyno turinio struktūros įtaką atpažinimo tikslumui. Šiandien pasaulyje daugelyje kalbų pirmiausia analizuojamas ir taikomas tik pirmos dešimties žodžių pavadinimų atpažinimas.
1`) A.Rudžionis. Computer recognition of isolated words in fixed length feature space. // Proc. of the XIth International Congress of Phonetic Sciences.- Tallinn, Estonia, 1987.-Vol.5.-pp 255 - 258.
4.1.3. Požymių analizė suvokimo eksperimentuose
Problema ir jos sprendimas. Nuo maždaug 1980 metų ėmė vyrauti požiūris, kad kalbos signalų aprašymui tinkamiausi yra kepstro požymiai. Galutinis atsakymas nėra žinomas ir šiandien, ypač galvojant apie klausos modeliais paremtus požymius. Vienok, naudojant sukauptas technologines priemones, buvo plėtojama filtrinių požymių analizė pagal suvokimo kriterijus,taikant vokoderinės technikos principus [1]. Po to buvo išplėsti eksperimentai, nustatant filtrinių požymių empirines suvokimo priklausomybes [2,3,4].
Rezultatai. 1 lentelėje pagal [3] pateikiamos skiemenų aiškumo ( syllable inteiligibility ) S įvertinimo kreivės, kai keičiamas filtrinių požymių skaičius n, tų parametrų fiksavimo žingsnis T.
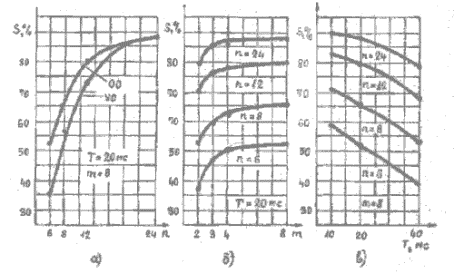
1 pav. Skiemenų aiškumas ( keičiamas filtrinių požymių skaičius ir
filtrinių požymių diskretizavimo dažnis )
Darbo reikšmė. Parodyta aiški požymių skaičiaus ir požymių diskretizavimo dažnio tarpusavio įtaka suvokimui. Šiuo metu yra plečiama nuodugnesnė požymių analizė, prognozuojant įvairesnių požymių kombinavimą .
Literatūra
1. K. Ratkevičius, A. Rudžionis. Suspaustų kalbos signalų kokybės rodiklių įvertinimas. // ARSO medžiaga. Kaunas, 1986, p. 45 - 46 ( rusų k. ).
2. K. Ratkevičius, A.Rudžionis. A relationship between the quality of vocoded speech and its compression rate. // Proc. of the XIth International Congress of Phonetic Sciences.- Tallinn, Estonia, 1987.-Vol.5.-pp.314 - 317.
3. K. Ratkevičius, A. Rudžionis. Perceptyvus kalbos signalų požymių įvertinimas. // Kalbos signalų automatinis atpažinimas ir sintezė. Kijevas, 1989, p. 53 - 57 (rusų k.).
4. K.Ratkevicius and A.Rudzionis. Some investigation on the vocoded speech perception and encoding. // Proc. of the Third Australian International Conference on Speech Science and Technology. Melbourn, November 1990, pp. 52 - 56.
4.1.4. Projekcinis atpažinimas
Problema ir jos sprendimas. Buvo suformuluotas fonetiškai motyvuotas projekcinis atpažinimo metodas [1]. Jis paremtas automatinių signalo skaidymu į fonetinius vienetus, tai priešpastatant populiariu tebeliekančiam tolydinio tankio paslėptų Markovo grandinių modeliui CD HMM ( continuous density hidden Markov model ). Fonetinė motyvacija paaiškinama pradinių požymių vektorių sekos skaidymu į veik fonetinius segmentus.
Rezultatai. Pradiniai rezultatai parodė, kad atpažinimo tikslumas nemažėja, kol segmentavimo priemonėmis požymių vektorių seka netampa mažesne už reikšmingų akustinių – fonetinių reiškinių skaičių frazėje. Vėliau buvo gauti esminiai patobulinimai “vidurkinant” keletą tų pat lingvistinių vienetų ištarimus [2,3,4,5], t.y. suvedant šį modelį beveik iki parametrinio. Lentelėje pagal [5] pateiktos atpažinimo klaidos .
1 lentelė. 100 žodžių atpažinimo klaidos, vidurkinant N ištarimų
( F filtrų, C kepstro požymiai, S stacionarus,
T pereinamieji segmentai )
|
|
Požymiai |
|||
|
N |
FS |
CS |
FS&FT |
CS&FT |
|
1 |
2.19 |
2.12 |
1.10 |
0.90 |
|
2 |
1.28 |
1.07 |
0.63 |
0.47 |
|
3 |
0.86 |
0.70 |
0.39 |
0.28 |
Darbo reikšmė. Šis modelis buvo pertvarkytas į unikalų pilnai fonetinio atpažinimo modelį ( žiūr. 4.1.6. ), o pastaruoju laiku vis aiškesnėmis tampa bendriausio kalbos atpažinimo modelio CD HMM ribos. Vidurkinimas projekciniame atpažinime[2-5] gali būti panaudotas, kaip viena iš galimų alternatyvų, pajėgių HMM modeliui suteikti naujų galimybių.
Literatūra
S.Noreika and A.Rudzionis, “ Phoneme-like model of speech signal “, Proc. of the XIIth International Congress of Phonetic Sciences. Aix-En-Provence, France, 1991,vol. 4,pp 490-493.
A.Rudzionis, “ Recognition by averaged templates “, COST 249 Continuous Speech Recognition Over The Telephone, Draft Minutes of the 1st Management Committee Meeting, Brussel, Belgium, 1994, pp. 41-47.
A.Rudzionis,V.Rudzionis, “ Phonetical segmentation and averaging of the utterances in speech recognition”, COST 250 Speaker Recognition in Telephony. Draft Minutes of 3rd Management Commitee Meeting, Lausanne, Switzerland, 1995, pp. 62-65.
A.Rudžionis, V. Rudžionis. Izoliuotų žodžių atpažinimas vidurkinant fonetiškai segmentuotus kalbinių signalų parametrus. // Informacinės technologijos - 97, Kaunas, Technologija, 1996. - P. 168 - 174.
A.Rudžionis. Projection-based speech recognition. // Defence Technologies from Lithuania. ISBN 9986-738-13-X. Vilnius, Senamiesčio Spaustuvė, 2000, p.150-152.
4.1.5. Pilnai fonetinis atpažinimas
Problema ir jos sprendimas. Jei norimas atpažinti balso komandas būtų galima vaizduoti tik tekstiniu pavidalu, tai būtų didelė pažanga, nes paprastai komandos etalonas yra labai griozdiškas. Apie 1990 metus projekcinis algoritmas buvo modifikuotas taip, kad etalonai buvo vaizduojami tik jų fonetinėmis transkripcijomis ir atlikti vieno diktoriaus balso komandų atpažinimo eksperimentai[1,2].
Buvo nagrinėti du fonetinių vienetų transkripcijoms rinkiniai. Pirmu atveju buvo vertinami PN = 23 fonetiniai vienetai ( jų kiek mažiau negu normaliame tekste, nes afrikatės buvo sutapatintos su frikatyviniais ) ir PN = 16, kur visi sprogstamieji priebalsiai buvo žymimi vienu simboliu. Toliau buvo nagrinėti PTV=7 fonetinio apmokymo variantai, besiskiriantis fonetinių kontekstų perdengimu. Balso komandos buvo parenkamos visai atsitiktinai.
Rezultatai. Lentelėje pagal [3] pateiktos 200 balso komandų atpažinimo klaidos. Geriausi rezultatai (mažiau nei 1 % klaidų) gauti, kai buvo labai rūpestingai atliktas fonetinio apmokymo kontekstų parinkimas, t.y. fonetinį vienetą vaizdavo 6 – 8 klasteriai parinkti iš 40 – 100 kontekstų. Be to efektyviau buvo naudoti tik 16 fonetinių vienetų. Taigi labai maža atpažinimo klaidą gauta, vaizduojant komandos etaloną tik 32 bitais ( 8 fonemos /žodžiui * 4 bitai/fonemai ).
1 lentelė. 200 balso komandų atpažinimo klaidų skaičius, naudojant pilnai fonetinį atpažinimo modelį
|
|
Fonetinis apmokymas, PTV |
||||||
|
PN |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
23 |
12.5 |
5.5 |
1.6 |
1.4 |
2.2 |
4.5 |
1.6 |
|
16 |
9.4 |
4.7 |
0.9 |
0.9 |
1.8 |
2.8 |
1.4 |
Darbo reikšmė. Šie rezultatai lieka unikaliais, o darbą reikia atnaujinti derinant su paslėptomis Markovo grandinėmis.
1. S.Noreika and A.Rudzionis. Phoneme-like model of speech signal. // Proc. of the XIIth International Congress of Phonetic Sciences. Aix-En-Provence, France, 1991, vol.4, pp 490-493.
2. A.Rudzionis. Isolated word recognition by fully phonetical word template. // Contribution to the COST232 final report. - 1994. - P. 11-13.
3. A.
Rudžionis. Fully phonetic projection-based speech recognition. // Defence
Technologies from Lithuania. Vilnius, Senamiesčio Spaustuvė, 2000, pp.149.
4.1.6. Fonemų diskriminacija ir konteksto reikšmė
Problema ir jos sprendimas. KTU kalbos signalų tyrimo grupėje fonemų diskriminacija visada buvo dėmesio centre. Jau nuo 1985 buvo [1,2,3] palyginti klasifikatoriai ( Euklido, Machalanobio matai, įvestas dichotominis klasifikatorius drauge su požymių erdvės optimizavimu ) ir pastebėta fonemų diskriminavimo konkrečiame kontekste svarba. Šie darbai buvo plečiami tolau [4,5,6], o efektyviausi rezultatai parodyti 4.1.10 skirsnyje.
Rezultatai. Jie buvo išdėstyti KPI ( dabar KTU) ataskaitose. Buvo gauta daugiadiktorinio apie 2% dydžio sunkiai skiriamų fonemų prieš tris kontrastingiausius balsius A,U,I klaida. Pereinant nuo atviro balsio A iki uždaro I kontekstų, teko smarkiai modifikuoti požymius bei įvesti sudėtingesnius klasifikatorius.
Darbo reikšmė. Suformuluoti svarbus, eksperimentais pagrįsti, fonemų diskriminavimo principai.
1. A.Rudžionis. Fonetinių vienetų skyrimo analizė keičiant apmokymo duomenis ir diskriminantes. // ARSO medžiaga. Kaunas, 1986, p. 26 - 27 ( rusų k. ).
2. A.Domatas, A. Rudžionis, N. Ezerskis. Dichotomijų panaudojimas fonemų skyrimui. // ARSO medžiaga. Kaunas, 1986, p. 35 - 35 (rusų k.).
3. A.Domatas and A.Rudzionis. Towards more reliable automatic recognition of the phonetic units. // Proc. of the XIIth International Congress of Phonetic Sciences. Aix-En Provence, France,1991,vol.4,pp 478-481.
4. A.Rudzionis, V. Rudzionis. Phoneme discrimination analysis. // Speech Technology Today, IX Session of the Russian Acoustical Society, 26 - 28 January 1999, Moscow, p. 62 - 65.
5. V.Rudžionis. Klasifikatorių palyginimas viendiktoriniam fonemų klasifikavimui. // Informacinės technologijos - 94, Kaunas, KTU, 1994.
6. V.Rudžionis. Įvairių klasifikatorių ir analizatorių palyginimas daugiadiktoriniame fonemų atpažinime. // Informacinės technologijos - 95, Kaunas, KTU, 1995. - P. 87-93.
4.1.7. Diskretinis HMM modelis
Problema ir jos sprendimas. Jau senokai buvo pastebėta, kad automatiškai labai sunkiai skiriami žodžiai gali būti efektyviai klasifikuojami, jei pritaikomi specifiniai konkrečią žodžių porą skiriantis požymiai. Darbe [1], tai buvo panaudota rusiškų skaičių pavadinimų 12 -“ dvenadsatj ” ir 13 “ trinadtsatj ” atpažinimui. Naudojant bendras atpažinimo schemas, šie žodžiai yra beveik neatskiriami, tačiau, pritaikius R garso identifikavimo požymius, pavyko šią žodžių porą automatiškai klasifikuoti apie 98% tikslumu, kai juos tardavo bet kuris diktorius.
Prieš porą dešimtmečių buvo pradėtas naudoti parametrinis kalbos atpažinimo modelis – paslėptos Markovo grandinės HMM. Gana ilgai buvo tiriama diskretinė šio modelio versija, kai požymiai buvo diskretizuojami vektorinio kvantavimo būdu. Vienok paaiškėjo, kad vektorinis kvantavimas kiek pagadina požymius ir buvo pereita prie tolydaus tankio Markovo modelių CD HMM, tačiau tampa aišku, kad ir ši metodika nėra ideali. Todėl buvo bandoma modeliuoti diskretinius HMM [2], viliantis, jog pavyks suformuoti žymiai efektyvesnius fonetinio klasifikavimo būdus.
Nagrinėtas žodis MADONA ir keletas kitų dirbtinių žodžių, kurie skiriasi tik viena raide ( MATONA, NADONA ir pan ). Žodžiai buvo dirbtinai “užtiukšminami”, sukuriant fonemų pakartojimus, įterpimus ir praleidimus. Pvz., žodis MADONA galėjo tapti seka MKMAAAAAJOOZOOOONNA, kur raidė D yra visai praleista. Apmokius diskretinį HMM pagal sugeneruotas sekas, buvo atliekamas atpažinimo testas pagal kitas sugeneruotas sekas, naudojant įprastą integralų atpažinimo kriterijų ir lokalų kriterijų, kur Viterbi atpažinimo schemoje lyginamos tik tos būsenos, kurios skiria žodžių porą ( pvz. poroje MADONA ir MATONA yra lyginamos tik raides D ir T atitinkančios būsenos ).
Rezultatai. 1 lentelėje pagal [2] yra pateiktos kelių žodžių atpažinimo klaidos, kurios rodo, kad, panaudojus lokalų diskriminavimo matą, galima radikaliai pagerinti automatinį fonetiškai artimų žodžių diskriminavimą.
1 Lentelė. Atpažinimo klaida % pagal integralų (I) ir lokalų (L)
matus, hM=8
|
hp |
Žodis |
K l a i d a % |
|
|
|
|
I |
L |
|
0 |
NADONA |
21.5 |
4.39 |
|
0 |
MATONA |
21.5 |
5.88 |
|
0 |
MADONU |
21.5 |
8.50 |
|
1 |
NADONA |
8.1 |
0.01 |
|
1 |
MATONA |
14.5 |
0.05 |
|
1 |
MADONU |
6.2 |
0.03 |
Darbo reikšmė. Šie rezultatai rodo, kad gerokas fonemų diskriminavimo pagerinimas gali sąlygoti esminę atpažinimo pažangą.
1. Segmentinės kalbos signalų analizės sistemos kūrimas. // KTU mokslinio darbo ataskaita. Reg. Nr. 01860135311. Kaunas 1988 ( rusų k. ).
2. Kalbos ir diktoriaus atpažinimas telefonijoje. // VSMF remiamo mokslinio KTU darbo ataskaita. Reg. Nr. BK 57E112, Kaunas, 1995
4.1.8. Pašalinių garsų atmetimas ( out of vocabulary ).
Problema ir jos sprendimas. Klausydamas jį dominančios kalbinės informacijos, žmogus sugeba ignoruoti pašalinius pokalbius, triukšmus, muzikinius garsus ar panašiai, žinoma, jei pastarieji nėra pernelyg intensyvūs. Tai reiškia, kad reikia turėti galimybę atmesti įvairius akustinius garsus, kurių nėra kompiuterinio dialogo žodyne. 1987 metais buvo atlikti pirmi eksperimentai šiuo klausimu. [1].
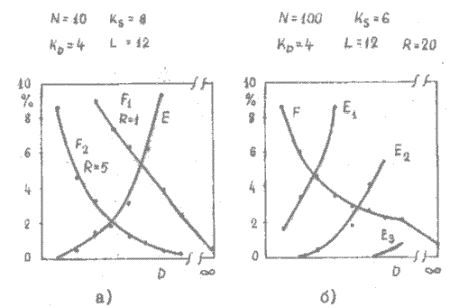
1 pav. Atpažinimo F ir pašalinių garsų E priėmimo klaidos vieno diktoriniaus atpažinime.
D – slenkstis, N – žodyno dydis, E1 – to pat diktoriaus kiti žodžiai, E2 – kito bet kurie žodžiai,
E3 - muzika
Tinkamai parenkant atpažįstamų signalų panašumo slenkstį, tikrinama ar nagrinėjama komanda yra pakankamai panaši į kurią nors vieną iš leistinų komandų. Jei slenkstis pakankamai aukštas, tai atmetama ir dalis leistinų komandų, o jei šis slenkstis per žemas, atpažinimo įtaisas beprasmiškai reaguoja į pašalinius garsus. Kuo tikslesnis yra atpažinimo algoritmas, tuo efektyviau veikia ši procedūra.
Rezultatai. 1 pav. pagal [1] parodytos darbinio žodyno F atpažinimo ir pašalinių žodžių E registravimo klaidos, kai nustatomas tam tikras slenkstis D.
Darbo reikšmė. Šie darbai yra vis plečiami dėl jų praktinės svarbos.
1. A.Rudžionis. Izoliuotų žodžių, vaizduojamų fiksuoto ilgio vektoriais, atpažinimas. // Kalbos signalų informatika. Kijevas, 1989, p. 65 - 69 ( rusų k. ).
4.1.9. Kalbos signalų aptikimas
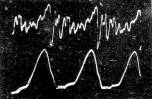
Problema ir jos sprendimas. Kalbėdamas mobiliu telefonu, dažnas gali pastebėti, kad yra “ nukandami “ atskiri žodžiai ar net frazės. Tai yra dėl to, kad ryšio sistemose yra įtaisytas ne visai idealus automatinis klasifikatorius “balsas – ne balsas” ( speech - nonspeech ). Atpažinimo uždaviniuose tai yra labai svarbi vieta, nes, pvz. jeigu “nukandome” PIN kodo dalį, tolesni veiksmai yra beprasmiai. Buvo tobulinamas “balsas – ne balsas” klasifikatorius, išnaudojant šnekamosios kalbos skiemeninę struktūrą.
Rezultatai. 1 pav. parodyti vokiečių kalba pasakytos rišlios skaičių sekos automatinio aptikimo eksperimentiniai rezultatai. Matome, kad frazės ribos gerai nustatomos kintant signalo lygiui ir netgi, esant labai stipriems ribojimo iškraipymams. Tai gerokai pranoko, duomenis pateikusios Daimler Benz Aerospace kompanijos, alternatyvų automatinio balso signalų aptikimo pavyzdį.
|
a) skirtingo lygio signalo aptikimas |
b) “klipuoto” signalo aptikimas |
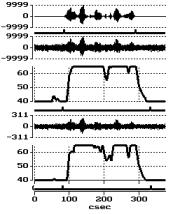
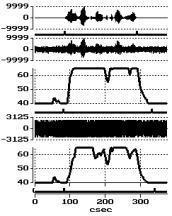
1 pav. Signalo aptikimas triukšmų fone, kai kinta jo lygis ( kairėje ) ir
stipriai iškraipyto užtriukšminto signalo aptikimas ( dešinėje ). Nuo viršaus:
a) švarus signalas; b) jo ribos; c) užtriukšmintas signalas;
d) signalo ribų požymis; e) automatiškai nustatytos ribos;
f) mažo lygio ( kairėje ) ar klipuotas signalas ( dešinėje );
g) signalo ribų požymis; h) automatiškai nustatytos ribos;
1. Lentelė. DASA ir KTU algoritmų efektyvumo palyginimas žodžių ribų aptikimo uždavinyje
|
Veikimo ribos |
DASA algoritmas |
KTU algoritmas |
|
SNR, dB |
12 |
0 |
|
energija P, dB |
10 |
30 |
Darbo reikšmė. Sukurtos balso signalų automatinio aptikimo priemonės gali būti naudojamos naujose atpažinimo sistemose.
1. A.Rudzionis, V. Rudzionis. Noisy speech detection and endpointing. // Voice operated telecom services. Do they have a bright future?, Workshop Proceedings, May 11-12, 2000, Ghent, Belgium, p. 79 - 82
2. A.Rudžionis. Detection of speech signals and endpointing in noise. // Defence Technologies from Lithuania. ISBN 9986-738-13-X.Vilnius, Senamiesčio Spaustuvė, 2000, p.143-145.
4.1.10. Reguliarizuota diskriminantinė analizė
Problema ir jos sprendimas. Daroma prielaida, kad populiariausio atpažinimo metodo – tolydinio tankio paslėptos Markovo grandinės CD HMM – lokalinė ( fonetinė ) skiriamoji geba negali būti geresnė, nei k-vidurkių KMN potencialios galimybės. Tai yra dėl to, kad CD HMM modelis yra paremtas požymių pavaizdavimų Gauso mišiniais. Buvo panaudota reguliarizuota diskriminantinė analizė, tikintis pagerinti automatinę fonemų klasifikaciją. Palyginimams taip pat naudojamas mūsų anksčiau įvestas dichotominis klasifikatorius ( diskriminantė ) DCH, Fišerio klasifikatorius FSH bei skirtingi požymiai ( LPC – autoregresinis kepstras, MFC – kepstras melų skalėje, F12 – rekursyviniai filtrai ) [1,2].
Bandymams buvo parinkti priebalsiai M, N prieš tris balsus A,U,I kuriuos sudiktavo 20 diktorių po 10 kartų kiekvieno balsio kontekste. Taip pat buvo analizuotos kelios reguliariazuotos diskriminacijos modifikacijos:
· SRDA - standartinis nuosavų reikšmių reguliarizavimas
· SLP - paprastas vienasluoksnis perceptronas panaudojamas praeito klasifikatoriaus išėjime;
· SR - reguliarizuojamos tiek nuosavos reikšmės, tiek ir nuosavi vektoriai;
· SR + SLP - paprastas vienasluoksnis perceptronas panaudojamas praeito klasifikatoriaus išėjime.
Rezultatai. 1 lentelėje palygintos kMN ir DCH diskriminantės. Pastaroji yra kiek pranašesnė, nes duotai priebalsių porai skirti yra naudojami ne visi požymiai, bet tik efektyviausi. Be to atviro balsio A kontekste priebalsiai klasifikuojami gerokai efektyviau, nei uždaro balsio I kontekste.
1 Lentelė. Priebalsių M,N skirtingų balsių kontekste klasifikavimo klaida (%).
Naudojami F12 požymiai, k-vidurkių (kMN) ir dichotomijų (DCH) diskriminantės.
|
Diskriminantė |
Balsis po priebalsio |
||
|
|
A |
I |
vid. |
|
KMN |
21.6 |
27.9 |
23.3 |
|
DCH |
11.4 |
19.8 |
16.3 |
2 lentelėje tie patys duomenis buvo klasifikuojami naudojant reguliarizuotas diskriminantes ir skirtingi požymių. Galima padaryti keletą svarbių išvadų:
· visur matoma, kad atviro balsio A kontekste priebalsiai klasifikuojami gerokai efektyviau, nei uždaro balsio I kontekste;
· gerai reguliarizuotos diskriminantės padeda esminiai sumažinti fonemų klasifikavimo klaidas, lyginant su kMN ar DCH ;
· “ užmiršti ‘ rekursyvinių filtrų F12 požymiai dažnai geresni už “modernius” kepstro požymius, pvz. priebalsių M,N balsio A kontekste klasifikavimo klaida sumažėja nuo 15,2% LPC kepstro atveju iki 3,6% F12 atveju.
2 Lentelė. Priebalsių M,N skirtingų balsių kontekste klasifikavimo klaida (%).
Naudojami kepstro LPC, MFC, filtrų F12 požymiai ir reguliarizuotos diskriminatės
|
Diskriminantė |
Balsio A kontekstas |
Balsio I kontekstas |
||||
|
|
LPC |
MFC |
F12 |
LPC |
MFC |
F12 |
|
FSH |
|
- |
14,7 |
|
- |
22,2 |
|
SRDA |
24,6 |
19,5 |
9,2 |
20,6 |
25,1 |
18,5 |
|
SLP |
17,2 |
13,1 |
6,6 |
14,1 |
17,6 |
12,1 |
|
SRM |
19,0 |
14,2 |
5,1 |
16,6 |
21,7 |
14,9 |
|
SR+SLP |
15,2 |
8,7 |
3,6 |
11,9 |
16,0 |
11,4 |
Darbo reikšmė. Šie rezultatai turėtų būti atidžiai plėtojami, nes tai gali būti esminis atpažinimo tikslumo pagerinimo šaltinis.
1) A.Rudzionis, V. Rudzionis. Phoneme recognition in fixed context using regularized discriminant analysis. // Eurospeech’99 Proceedings, ESCA 6th European Conference on Speech Communication and Technology, ISSN 1018-4074, Budapest, Hungary, September 5-9, 1999, p. 2745 - 2748.
2) A.Rudžionis. Phoneme recognition using regularized discriminant analysis. // Defence Technologies from Lithuania. ISBN 9986-738-13-X. Vilnius, Senamiesčio Spaustuvė, 2000, p.139-140.
4.2. Vilniaus universitetas
Vilniaus
universitete daugiausia buvo atliekami darbai, susiję su kalbos sinteze ir jos
taikymu akliesiems bei silpnaregiams. Buvo sukurtas lietuviškai kalbantis
sintezatorius “Aistis”.
4.2.1. Kalbos signalų apdorojimo priemonės
Problema ir jos sprendimas.
Kalbos signalų apdorojimui bei analizei reikia turėti patogias programines
priemones. Šiam tikslui pasaulyje yra sukurta daug instrumentų, tačiau norint
sudaryti kalbos sintezei pritaikytą fonetinių vienetų bazę reikalingos kai
kurios papildomos funkcijos.
Rezultatai. VU
vykdant projektą [ 1 ] buvo sukurta kalbos signalų apdorojimo programa
“Kalbame”, leidžianti įvesti kalbos signalą, nupiešti jo grafiką, spektrogramą,
pagrindinio tono grafiką, filtruoti ir karpyti signalą, pasiklausyti signalo ar
jo segmento, sintezuoti signalą iš segmentų.
Darbo reikšmė. Ši
programa buvo įdiegta kai kuriose mokslo institucijose: VU FilF, VPU ir kitur.
Būtent ši programa buvo naudojama sintezatoriaus Aistis fonetinių vienetų bazei
sudaryti.
1) Girdenis,
A., P. Kasparaitis, A. Pečeliūnaitė, P. Skirmantas, V. Undzėnas (1996). Lietuvių kalbos bei jos tarmių prozodinių reiškinių
ir fonemų alofonų analizė. Moksl. ataskaita. Lietuvos valst. mokslo ir
studijų fondas, registr. Nr. 94–081/3 G–1994 01 06. VU BKK. Vilnius.
4.2.2. Automatinis žodžių kirčiavimas
Problema ir jos sprendimas.
Kad sintezuota lietuvių kalba skambėtų suprantamai ir natūraliai, žodžiuose
turi būti teisingai sudėlioti kirčiai. Lietuvių kalba turi unikalią ir gana
sudėtingą kirčiavimo sistemą. Lietuvių kalbos gramatikose pateikiamos
kirčiavimo taisyklės nėra pritaikytos kompiuteriui, todėl reikia algoritmizuoti
lietuvių kalbos kirčiavimo taisykles ir realizuoti jas kompiuterinių programų
pavidalu.
Paprasčiausias
būdas kirčio vietai nustatyti yra saugoti kompiuterio atmintyje žodžius kartu
su kirčiavimui reikalinga informacija. Lietuvių kalbai toks metodas netinka,
nes žodžiai yra kaitomi. Tinkamesnis būdas – saugoti kompiuterio atmintyje
žodžių dalis (priešdėlius, šaknis, galūnes) kartu su žodžių darybai, kaitymui
ir linksniavimui reikalinga informacija ir sukurti žodžių darybos, kaitymo ir
kirčiavimo taisykles realizuojančius algoritmus.
Rezultatai. Remiantis
[ 3 ] ir [ 4 ] buvo sudarytos beveik 9000 veiksmažodžių kamienų, virš 53000
daiktavardžių ir būdvardžių kamienų, virš 2300 nekaitomų žodžių, daiktavardžių,
būdvardžių ir veiksmažodžių galūnių, veiksmažodžių priešdėlių duomenų bazės.
Sukurti žodžių darybos, kaitymo ir kirčiavimo algoritmai realizuoti
kompiuterinių programų pavidalu ([ 1 ], [ 2 ]). Šie algoritmai teisingai
kirčiuoja virš 80% atskirų žodžių. Likę žodžiai paliekami nekirčiuoti, nes be
konteksto jų negalima vienareikšmiškai sukirčiuoti. Kirčiavimo klaidų beveik
nedaroma.
Darbo reikšmė. Žodžių kirčiavimo algoritmai sėkmingai įdiegti sintezatoriuje “Aistis”, be to juos galima būtų pritaikyti ir kitiems tikslams, pvz., kirčiavimo mokymui. Algoritmus galima būtų patobulinti papildant vieno kirčiavimo varianto išrinkimu iš daugelio priklausomai nuo konteksto.
Detalesnis kirčiavimo algoritmų aprašymas pateiktas priede A.
1) Kasparaitis, P. (2000). Automatic
Stressing of the Lithuanian Text on the Basis of a Dictionary. Informatica, 11(1), 19-40.
2) Kasparaitis, P. (2001). Automatic
Stressing of the Lithuanian Nouns and Adjectives on the Basis of Rules. Informatica, 12(2), 315-336.
3) Keinys, St. (Red.), J. Klimavičius, J.
Paulauskas, J. Pikčilingis, N. Sližienė, K. Ulvydas, V. Vitkauskas (1993). Dabartinės lietuvių kalbos žodynas.
Mokslo ir enciklopedijų leidykla. Vilnius.
4) Kvietkauskas, V. (Red.), A. Kinderys,
V. Viluveitas (1985). Tarptautinių žodžių
žodynas. Vyriausioji enciklopedijų redakcija. Vilnius.
4.2.3. Automatinis teksto transkribavimas
Problema ir jos sprendimas.
Teksto transkribavimas yra viena iš kalbos sintezės pagal tekstą sudedamųjų
dalių. Jo metu tekstas pakeičiamas fonetinių vienetų seka. Tai reikalinga
todėl, kad žodį sudarančios raidės dažnai nenusako tiesioginio perėjimo prie
garsų, nes rašybos taisyklės paprastai būna daug konservatyvesnės (lėčiau
kintančios) nei šnekamoji kalba. Lietuvių kalbos transkripcija yra unikali,
t.y. nesutampanti su jokios kitos kalbos transkripcija, todėl reikia sukurti
transkribavimo algoritmą.
Lietuvių kalbai
netinka žodynu paremti metodai, nes lietuvių kalbos žodžiai yra kaitomi, be to,
lietuvių kalbos transkripcija yra gana nesudėtinga, jei laikysime, kad žodžiai
jau suskiemenuoti ir sukirčiuoti. Lietuvių kalbai geriau taikyti formaliomis taisyklėmis
paremtus metodus.

Rezultatai. Buvo
sudarytas taisyklių, turinčių pavidalą
rinkinys (740
taisyklių) bei sukurtas šias taisykles interpretuojantis algoritmas [1]. Šis metodas beveik
nedaro transkribavimo klaidų, išskyrus klaidas, atsiradusias dėl skiemenavimo
ir kirčiavimo klaidų, o taip pat tarptautiniuose žodžiuose, kuriuose naudojami
lietuvių kalbai nebūdingi garsai, pvz., trumpas nekirčiuotas /o/.
Darbo reikšmė. Šis
taisyklių rinkinys ir transkribavimo programa sėkmingai naudojami sintezatoriuje
“Aistis”. Pasikeitus fonetinių vienetų bazei reikėtų atitinkamai pakeisti
transkribavimo taisykles, taisyklių interpretavimo algoritmas galėtų likti
nepakitęs.
1. Kasparaitis, P. . Transcribing of the
Lithuanian Text Using Formal Rules. Informatica,
10(4), 367-376. 1999
4.2.4. Fonetinių vienetų bazė
Problema ir jos sprendimas.
Kalbos signalo formavimui sintezatorius naudoja fonetinių vienetų bazę.
Pirmiausia reikia pasirinkti sintezės metodą. Paskutiniu metu itin populiarus
konkatenacinis metodas, kuriame naudojami natūralios diktoriaus kalbos
segmentai. Lietuvių kalbos fonetinė struktūra unikali, t.y. nesutampa su jokia
kita kalba. Sudarant fonetinių vienetų bazę negalima remtis vien fonetiniais ar
fonologiniais lietuvių kalbos tyrimais, reikia atlikti specialius tyrimus
siekiant nustatyti kiek, kokių garsų, iš kokių kontekstų ir kaip reikia
iškirpti, kad juos jungiant gautume kokybišką sintezuotą kalbą.
Fonetinių
vienetų bazė sudaroma taip: sudaromas žodžių ar sakinių, kuriuose būtų visi
reikalingi fonetiniai vienetai, sąrašas. Sudarytą sakinių sąrašą perskaito
diktorius ir jo balsas skaitmeniniu būdu įrašomas į kompiuterį. Po to iš šių
įrašų iškerpami fonetiniai vienetai.
Rezultatai. Panaudojant
diktoriaus J. Šalkausko balsą buvo sudaryta fonetinių vienetų bazė, kurioje yra
476 fonetiniai vienetai. Fonetinių vienetų bazę sudarė prof. A. Girdenis (VU
Filologijos fak.). Naudojami įvairaus ilgio segmentai: alofonų dalys, alofonai,
dvibalsiai ir dvigarsiai. Segmentai apima ir perėjimus tarp garsų. Nors fonetinių
vienetų bazė sudaryta gana kruopščiai, ateityje ją reikėtų tobulinti, nes:
1) Trūksta kai
kurių fonetinių vienetų: neskiriama kai kurių ilgųjų balsių ir dvibalsių
tvirtapradė ir tvirtagalė priegaidės, pvz., brólis - brõkas, píenas –
piẽnė; kai kurie balsiai šalia nosinių priebalsių skamba kitaip, pvz.,
mama;
2) Yra tik po
vieną kiekvieno fonetinio vieneto realizaciją, o galima turėti po kelis su
skirtingom intonacijom, kalbėjimo greičiais, ir pagal situaciją parinkti
tinkamiausią;
3) Fonetiniai
vienetai buvo kerpami be konteksto, kontekstas gali būti reikalingas norint
sklandžiau jungti garsus naudojant, pvz., TD-PSOLA algoritmą. Iki šiol joks
garsų jungimo suglodinimo algoritmas nebuvo naudojamas;
4) Garsas buvo
iš pradžių įrašytas į magnetofono juostą, o po to diskretizuotas. Galima būtų
iš karto įrašyti skaitmeniniu pavidalu didesniu dažniu.
5) Kai kuriuos
dažniausiai vartojamus žodžius galima ne sintezuoti, o įrašyti ir atkurti.
Lietuvių kalboje apie 500 dažniausiai naudojamų žodžių žodynas padengia apie
33% tekste sutinkamų žodžių, o 5000 žodžių žodynas padengia apie 66% [ 1 ].
Darbo reikšmė. Ši
fonetinių vienetų bazė įdiegta sintezatoriuje “Aistis”. Ateityje verta sudaryti
naują fonetinių vienetų bazę remiantis sukaupta patirtimi ir atsižvelgiant į
aukščiau paminėtas pastabas.
1. Marcinkevičienė, R. (2000). Tekstynų
lingvistika. VDU leidykla. Kaunas.
4.2.5. Sintezuotos kalbos kokybės įvertinimas
Problema ir jos sprendimas.
Norint įvertinti sintezuotos kalbos kokybę ir palyginti ją su kitais sintezatoriais
ar diktoriumi, reikia turėti tam tikrą tekstų rinkinį ir tų sintezatorių ar
diktoriaus balso įrašus, kuriuose įdiktuoti šie tekstai. Paprastai turi prasmę
lyginti tik tos pačios kalbos sintezatorius, todėl reikia turėti specialiai
lietuvių kalbai sukurtus testus.
Rezultatai. Buvo
sudarytos trys grupės po 30 sakinių, trys grupės po 30 žodžių ir trys grupės po
25 raides. Minėti sakiniai, žodžiai ir raidės buvo:
1) perskaityti diktoriaus Juozo
Šalkausko, 2) sintezuoti naudojant sintezatorių „Aistis”, 3) sintezuoti
naudojant „Aistį”, tačiau nekirčiuojant žodžių, 4) naudojant Dolphin Systems
for People with Disabilities sintezatorių „Apollo II”. Šie dvylika įgarsintų
sakinių, žodžių ir raidžių variantų pateikti [ 1 ]. Kalbos suprantamumui
įvertinti buvo pasitelkti klausytojai – 85 studentai nuo 20 iki 31 metų. Testus
sudarė ir testavimą atliko VU Filosofijos fakulteto doc. F. Laugalys. Žodžių ir
sakinių suprantamumo testo rezultatai pateikti lentelėje.
|
|
Atskiri žodžiai |
Žodžiai sakinyje |
Sakiniai |
|||||
|
|
Nesuprasta |
Klaidingai suprasta |
Teisingai suprasta |
Nesuprasta |
Klaidingai suprasta |
Teisingai suprasta |
Nesuprasta |
Teisingai suprasta |
|
Diktorius |
0,1% |
1,3% |
98,5% |
0,4% |
0,3% |
99,3% |
1,9% |
98,1% |
|
Apollo II |
24,1% |
23,8% |
52,1% |
28,3% |
5,6% |
66,1% |
56,6% |
43,4% |
|
Aistis |
3,7% |
8,2% |
88,1% |
4,2% |
2,6% |
93,2% |
16,6% |
83,4% |
|
Aistis be kirčiavimo |
10,5% |
12,7 |
76,8% |
16,9% |
4,5% |
78,6% |
37,8% |
62,2% |
Darbo
reikšmė. Šie testai gali būti naudojami ateityje
patobulintiems ar naujai sukurtiems lietuvių kalbos sintezatoriams įvertinti.
1. Kasparaitis, P. (2001). Lietuvių
kalbos kompiuterinė sintezė. Daktaro disertacija. Vilniaus universitetas,
Vilnius.
4.2.6. Automatinis teksto skiemenavimas
Problema ir jos sprendimas.
Kalbos sintezėje pagal tekstą prieš kirčiuojant ir transkribuojant lietuvių
kalbos žodį, jį reikia suskiemenuoti. Tai reikalinga todėl, kad kirčiavimo
taisyklėse kirčio vieta nusakoma kaip kirčiuoto skiemens numeris, o be to,
transkribuojant reikia atsižvelgti į skiemenų ribas, nes dvibalsius ir
mišriuosius dvigarsius gali sudaryti tik vienam skiemeniui priklausantys garsai.
Lietuvių kalboje skiemenavimas yra palyginti nesudėtingas uždavinys, didžiąją
dalį teksto galima suskiemenuoti remiantis lietuvių kalbos skiemens struktūra.
Tais atvejais, kai skiemens riba yra tarp dviejų balsių, galima pasinaudoti
priešdėlio atskyrimu ir balsių deriniais, kurie negali priklausyti vienam
skiemeniui.
Rezultatai. Sukurtas
skiemenavimo algoritmas leidžia beveik be klaidų skiemenuoti lietuvių kalbos
tekstą.
Darbo reikšmė. Algoritmas
įdiegtas sintezatoriuje „Aistis”. Skiemenavimo algoritmą galima pritaikyti ir
žodžių kėlimui, tačiau lietuvių kalbos žodžiai gali būti keliami ir morfemomis.
Skiemenavimo programą „Skie-muo” yra sukūrusi ir firma „Fotonija”.
1. Kasparaitis, P. (2001). Lietuvių
kalbos kompiuterinis sintezatorius „Aistis”. Garso korta 2001, KTU Technologija.
4.3. Lietuvos teismo ekspertizės centro Fonoskopinių ekspertizių skyrius
Mūsų šalyje teisminė ekspertizė
pagal balsą buvo pradėta daryti 1991 metais Lietuvos teismo ekspertizės
institute (dabartiniame Lietuvos teismo ekspertizės centre). Fonoskopinių
ekspertizių svarba ypatingai išaugo priėmus BPK papildymus dėl techninių
priemonių panaudojimo, atliekant operatyvinius veiksmus bei telefoninių
pokalbių perklausymą. Tokiu būdu atsirado teisinis pagrindas taikyti šios
srities specialias žinias, tiriant sunkius nusikaltimus, o garso ir vaizdo
įrašai įgavo įrodymų reikšmę.
Fonoskopinės ekspertizės naudoja skirtingų mokslo sričių
žinias: skaitmeninio signalų apdorojimo teorijos, akustikos, psichoakustikos,
elektronikos, garso technikos, matematinės statistikos, sprendimų priėmimo
teorijos ir kt. Fonoskopinių ekspertizių grupės darbo objektas yra garso
įrašai. Juose užfiksuotos žmogaus balso ir sakytinės kalbos savybės, garso ir
vaizdo įrašymo priemonių, kuriomis buvo padaryti šie garso įrašai, ypatybės bei
garsinė aplinka. Pagrindiniai ekspertizės tikslai šie:
·
Asmens tapatybės
identifikavimas pagal balsą, užfiksuotą tiriamajame (operatyviniame) ir
lyginamajame garso bei vaizdo įrašuose.
·
Garso įrašu autentiškumo
nustatymas. Tiriant pateiktą fonogramą siekiama nustatyti ar tai originalas, ar
kopija; ar įrašas ištisinis ir nėra sumontuotas.
·
Triukšmo slopinimas.
Panaudojant tam tikrų techninių bei programinių priemonių visumą, įrašas
išvalomas nuo pašalinių triukšmų, ir tuo pačiu pagerinamas jame užfiksuotos
kalbos suprantamumas.
·
Garsinės aplinkos, kurioje
padarytas pateiktas įrašas, nustatymas.
4.3.1 LTEC FES veikla ir esama būklė
Šių
uždavinių sprendimui Fonoskopinių ekspertizių skyrius 1990 – 1993 metais kartu
su Matematikos ir informatikos institutu vykdė mokslinė darbą “Fonoskopinės
ekspertizės metodologiniai ir metodiniai pagrindai”. Nuo 1993 metų Fonoskopinių
ekspertizių skyrius darbus tęsia savo jėgomis. Vykdant šią temą buvo atlikta
visa eilė mokslinių užduočių:
·
Asmens identifikavimo pagal
balsą automatizuotos sistemos ir metodikos, nepriklausančios nuo garso įrašu
kokybės, kūrimas (1993m.)[1];
·
Kalbos turinio atkūrimo
metodų iš užtriukšminto garso įrašo tyrimas (1992m.) [2];
·
Kalbos signalų parametrinių
aprašymų, naudojamų identifikuojant kalbantįjį, tyrimas (1993m.) [3];
·
Kalbančiojo tapatybės
identifikavimo, panaudojant tiesinės prognozės modelio parametrus, galimybės
(1994m.)[4];
·
Kalbančiojo identifikavimo,
panaudojant kalbos trakto ir sužadinimo signalo parametrus, galimybės (1995m.)
[5];
·
Triukšmo įtakos kalbančiojo
identifikavimo tikslumui tyrimas (1997m.)[6];
·
Fonetinių požymių sistemos
asmens identifikavimui pagal balsą kūrimas (1999m.) [7];
·
Skaitmeninių telefoninių
garso įrašų kokybės tyrimas, įvertinant pagrindinio tono ir sąlyginio atstumo
nustatymo tikslumą. (1998m.) [8];
·
Asmens identifikavimo
algoritmų tyrimas, naudojant balsų bazę “POLYCOST”. (1997m.) [9];
·
Asmens identifikavimo pagal
balsą foneminės požymių sistemos efektyvumo tyrimas (2000m.) [10].
Taip nuo 1991 metų
nuolat LTEC Fonoskopinių ekspertizių grupėje kuriama automatizuota darbo vieta
fonoskopinės ekspertizės uždavinių sprendimui. 4.3.1 pav. pateikta tokios darbo
vietos (AFEDV) blokinė schema. AFEDV sudaro profesionali garso atkūrimo ir
įvedimo/ išvedimo technika bei atitinkama programinė įranga.
Šiuo metu
naudojamos programinės dalies pagrindą sudaro programiniai paketai SIS (Speech
Interactive System) [11] ir SIVE. SIS programinis paketas savo ruožtu yra
sudarytas iš visos eilės programų, kurios skirtos kalbos signalų redagavimui,
analizei ir triukšmo slopinimui bei dalinai automatizuotam kalbos įrašų
pavertimui tekstu (Computer Transcreiber).
SIVE programinis paketas sudaro fonoskopinių ekspertizių
pagrindą: jame realizuoti atitinkami akustiniai asmens atpažinimo pagal balsą
metodai bei visa eilė pagalbinių programų, skirtų kalbos signalų apdorojimui.
Šio programinio paketo pagrindinėse programose yra realizuoti algoritmai, kurie
buvo sukurti ir ištirti atliekant aukščiau išvardintas mokslines užduotis [12].
LTEC Fonoskopinių ekspertizių skyriuje dabar yra 7 darbo vietos. Deja ne visos
darbo vietos sukomplektuotos atitinkama garso atkūrimo technika bei programine
įranga.
Nuo 1995 metų
Fonoskopinių ekspertizių skyriuje asmens atpažinimui pagal balsą naudojamas
kombinuotas metodas, kurį sudaro šie analizės metodai:
·
Audityvinė analizė;
·
Akustinė analizė;
·
Fonetinė – lingvistinė
analizė.
Atitinkamai akustinės analizės pagrindą sudaro du
pagrindiniai asmens atpažinimo pagal balsą metodai:
·
Pagrindinio tono ir jo
išvestinių parametrų skaičiavimas bei palyginimas;
·
Foneminis metodas. Asmens
identifikacinių požymių iš fonemų skaičiavimas ir palyginimas
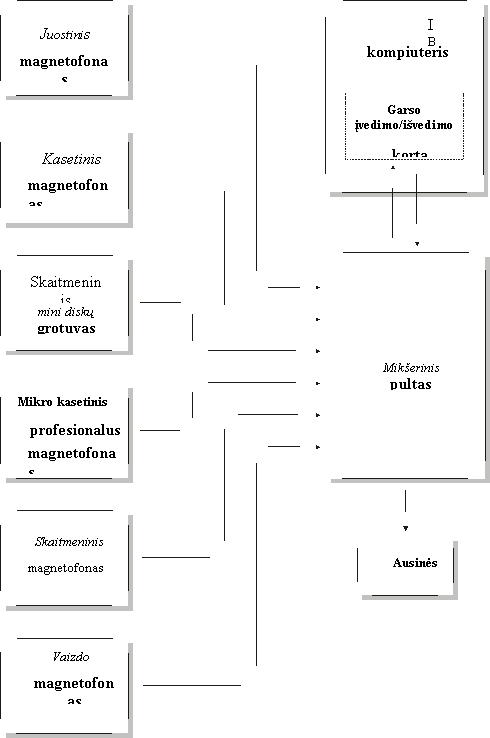
4.3.1 pav. AFEDV blokinė schema.
Kombinuotas asmens identifikavimo pagal balsą metodas šiuo
metu laikomas vienu iš perspektyviausių kriminalistikoje naudojamų metodų.
Prieš 2001 metais Prancūzijoje Lione vykusią 13-ąją Pasaulinę Interpolo
Kriminalistikos mokslų konferenciją atlikta viso pasaulio fonoskopinių
laboratorijų apklausa., kurioje dalyvavo 30 laboratorijų iš 21 šalies (tame
tarpe LTEC Fonoskopijos skyrius) [13]. Apklausos dalyviai turėjo nurodyti
kokius metodus naudoja asmens identifikavimui pagal balsą, atliekamų asmens
identifikavimo klausimų kiekį per metus, garso įrašų autentiškumo nustatymo
metodus, triukšmo slopinimo metodus ir su tuo susijusių atliktų klausimų kiekį
ir t.t Šioje ataskaitoje buvo pažymėta, kad LTEC asmens identifikavimui
naudojamas programinis paketas SIVE yra tarp geriausių, naudojamų
kriminalistinėje praktikoje [1], o atliktų asmens identifikavimo ekspertizių
kiekis didžiausias palyginus su visomis kitomis apklausoje dalyvavusiomis
laboratorijomis, tame tarpe ir JAV FTB laboratorija. LTEC Fonoskopijos skyrius
dalyvauja ENFSI WG SA darbe ir šio skyriaus darbo rezultatai pateikti 3.3.7
paragrafo 1 ir 2 lentelėje. Apibendrinant teigtume, kad LTEC Fonoskopinių
ekspertizių skyrius pasiekė neblogų rezultatų identifikuojant asmenį pagal jo
balsą. Visų pirma juos pavyko pasiekti todėl, kad kryptingai vykdomi moksliniai
tyrimai, kartu diegiant sukurtus metodus į ekspertinę praktiką. Taip pat viena
iš minėtų pasiekimų priežasčių yra ta, kad buvo orientuojamasi į AFEDV kūrimą
PC bazėje, o ne į atskirų prietaisų
pirkimą. Asmens pagal balsą identifikavimo efektyvumą taip pat nulėmė
santykinai paprastos ir tuo pat metu duodančios pakankami gerus rezultatus
identifikacinių požymių sistemos sukūrimas [14].
Garso įrašu autentiškumo nustatymui
yra naudojami įprastiniai standartizuoti metodai [15].
Šiuo metu triukšmo slopinimui naudojami
SIS esantys metodai bei procedūros ir taip pat specialus programinis paketas
SOUNDCLINER PRO, kuriame realizuoti įvairūs skaitmeniniai filtrai programiniu
pavidalu.
Reikia pastebėti, kad kaip rodo
apklausa [13], LTEC Fonoskopinių ekspertizių skyriaus pasiekimai triukšmo
slopinimo srityje yra gana kuklūs. Tai, kad LTEC FES atlieka mažai triukšmo
slopinimo ir tuo pačių garso suprantamumo gerinimo ekspertizių galima
paaiškinti tokiomis priežastimis. Visų pirma, jeigu garso įrašas
užtriukšmintas, tai su dabar naudojama technologija neįmanoma identifikuoti
asmens pagal balsą. Taip pat, pagal nusistovėjusią praktiką, ekspertai
dažniausiai sprendžia pateikto garso įrašo teksto atstatymo (iššifravimo)
klausimą, kuris dažniausiai susijęs su triukšmo slopinimo technologijų taikymu.
Todėl vien tik triukšmo slopinimo klausimai beveik neatliekami.
4.3.2 Problemos ir tolesnio vystymo perspektyvos LTEC FES
Pagrindinė asmens identifikavimo
pagal balsą problema, kaip jau ir buvo minėta 3.3.7 paragrafe, tai - garso
įrašymo sąlygų įtakos identifikavimo tikslumui mažinimas. Taip pat reikia
atlikti tyrimus, skirtus naujų identifikacinių požymių paieškai. Mokslinių
tyrimų, skirtų įvairių identifikacinių požymių sistemų analizei bei kūrimui,
nėra. Taip pat aktualus uždavinys - asmens identifikavimas, turint trumpą garso
įrašą (15 žodžių ir mažiau). Kita aktuali problema - tai naudojamos žodinės
(verbalinės) išvadų skalės (kategoriškai duoto asmens balsas, kategoriškai
"ne", tikėtina duoto asmens balsas, tikėtina "ne" ir
atmetimas) griežtesnis susiejimas su konkrečiomis skaitinėmis parametrų,
kuriais aprašomas balsas, reikšmėmis: tam tikros metodikos arba procedūros
sukūrimas, kuri vienareikšmiškai susietų duodamų išvadų skalę su skaitinėmis
analizės rezultatų išraiškomis. Aišku šis uždavinys yra labai sudėtingas, jo
sprendimui reikalingos kriminalistinės balsų bazės bei dideli statistiniai
tyrimai ir tam tikras teorinis pagrindimas.
Šiuo metu LTEC Fonoskopijos skyriuje
susidarė didesnė nei pusės metų eilė (7-10 mėnesių) ekspertizių atlikimui.
Todėl naujų kalbinių technologijų, kurios leistų pagreitinti ekspertizių
atlikimą ir įsisavinti naujų fonoskopinės ekspertizės klausimų sprendimą,
sukūrimas yra neatidėliotinas ir labai aktualus uždavinys.
Vienas iš aktualiausių uždavinių garso įrašų autentiškumo
nustatyme - skaitmeninių garso įrašų autentiškumo nustatymas. Šis uždavinys yra
gana sudėtingas, todėl, kad skaitmeninių garso įrašu autentiškumo nustatymas
yra kompleksinis uždavinys. Čia susiduriama su taip vadinamų skaitmeninių
"pėdsakų" (Digital Evidence) tyrimu. Tai yra jau nepakanka vien tik
garso signalų analizės metodų (FFT, sonogramų, signalogramų, impulsinių
charakteristikų tyrimo ir t.t), o reikalingi tam tikri kriptografinės analizės
(kontrolinės sumos, skaitmeniniai "vandens" ženklai ir t.t.) metodai
[15] bei specialūs algoritmai, kurie jau garso įrašo įrašymo metu užtikrina
tokių įrašų autentiškumą. Tai gana sudėtinga ir aktuali problema ir šios
problemos LTEC FES vien tik savo jėgomis nepajėgus spręsti. Tam reikalingas
tiek suinteresuotų žinybų, tiek mokslininkų bendras darbas.
Fonoskopijoje
susiduriama su labai įvairios prigimties užtriukšmintais garso įrašais. Šių
triukšmų pobūdis dalinai jau buvo aprašytas toliau. Taip pat reikia pastebėti,
kad dažniausiai tyrimui pateikiami mono įrašai, o turimi filtravimo metodai
efektyviai dirba turint atraminį signalą arba, kai turime to paties garso
šaltinio įrašą, padarytą dviem mikrofonais. Todėl svarbu panauduoti tokias
triukšmo slopinimo ir tuo pačiu kalbos suprantamumo gerinimo technologijas,
kurios būtų efektyvios, turint tik mono garso įrašus. Labai svarbu sukurti
tokias technologijas, kurios pagerintų kalbos signalų suprantamumą ir tuo pačių
turėtų mažą įtaką asmens identifikaciniams požymiams. Ateityje reikėtų visų
pirma sukurti ekspertui patogias ir lengvai suprantamas procedūras triukšmo
slopinimui bei garso įrašų suprantamumo gerinimui. Tuo pat metu būtina kurti
tokią asmens identifikavimo pagal balsą pažymių sistemą, kuri filtravimo ir
garso įrašymo kanalų normalizavimo atvejais duotų pakankamai gerus rezultatus.
LTEC
FES siekia dalyvauti sprendžiant minėtus uždavinius. Tačiau dažnai tam
reikalingas kooperavimasis su kitomis Lietuvos mokslinėmis institucijomis bei
suinteresuotomis tarnybomis.
Literatūra
1) LTEI. Mokslinio darbo: Asmens identifikavimo pagal balsą
automatizuotos sistemos ir metodikos, nepriklausančio nuo garso įrašu kūrimas,
ataskaita, 1993.
2) LTEI. Mokslinio darbo: Kalbos turinio atkūrimo metodų iš
užtriukšminto garso įrašo tyrimas. 1992.
LTEI. Mokslinio darbo: Kalbos signalų parametrinių
aprašymų, naudojamų identifikuojant kalbantįjį, tyrimas.1993.
3) LTEI. Mokslinio darbo: Kalbančiojo identifikavimas,
panaudojant tiesinės prognozės modelio parametrus. 1994.
4) LTEI. Mokslinio darbo: Kalbančiojo identifikavimas,
panaudojant kalbos trakto ir sužadinimo signalo parametrus. 1995.
5) LTEI. Mokslinio darbo: Triukšmo įtakos kalbančiojo
identifikavimo tikslumui tyrimas. 1997.
6) LTEI. Mokslinio darbo: Fonetinių požymių sistemos asmens
identifikavimui pagal balsą sukūrimas. 1999.
7) LTEI. Mokslinio darbo: Skaitmeninių telefoninių garso
įrašu kokybės tyrimas, įvertinant pagrindinio tono ir sąlyginio atstumo
nustatymo tikslumą. 1998.
8) LTEI. Mokslinio darbo: Asmens identifikavimo algoritmų
tyrimas, naudojant balsų bazę “POLYCOST”. 1997.
9) LTEI. Mokslinio darbo: Asmens identifikavimo pagal balsą
foneminės požymių sistemos efektyvumo tyrimas. 2000.
10) Speech Interactive System (SIS). System for editing,
analysis and noise reduction of speech signals. Users guide. Speech Technology
Centre, St.-Petersburg, 2000, p.1-125.
11) SIVE 6.2. Users Manuel. Forensic Speaker Identification
and Verification Software Package. TECHNOGAMA, Vilnius, 2000, p.1-30.
12) A.P.P. Broeders, Forensic Speech and Audio analysis. 1998
to 2001 Review. Proceedings of the 13 th INTERPOL Forensic Science Symposium,
Lyon, France, 16-19 October 2001, p.1-26.
13) B.Šalna. Paketas asmens identifikavimui SIVE.
Informacinės technologijos verslui 2001. Konferencijos pranešimų medžiaga.
Kaunas, 2001 m., gegužės 30d., p.112-114.
14) AES Standard for Forensic Purposes-Criteria for the
Authentication of Analog Audio Tape Recordings. Journal of the Audio
Engineering Society, 200, vol.48, No.3, p.204-214.